

1.域适应简介
域适应是迁移学习中最常见的问题之一,域不同但任务相同,且源域数据有标签,目标域数据没有标签或者很少数据有标签。
域适应通过将源域和目标域的特征投影到相似的特征空间,这样就可以拿源域的分类器对目标域进行分类了
下面拿二分类做说明,如下图:
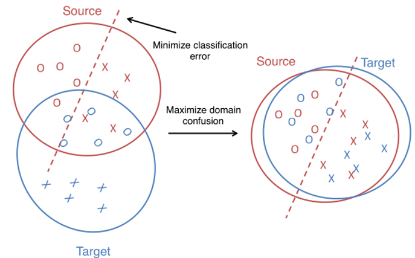
图中红圈是源域,蓝圈是目标域,圆圈和叉是不同特征的数据,源域的分类器将源域的数据分为两类,即虚线所示。
此时如果拿源域的分类器在目标域上分类,从图中可以看到,效果很差。
那怎么办呢,有一种方法就是把源域和目标域的分布对齐,如图片右边所示,源域目标域的分布相似(即相似特征的数据分布在相近的位置),这样就可以直接拿源域的分类器对目标域进行分类了。
训练过程域对抗生成网络 GAN 相似
同时训练两个模型:一个用来提取目标域特征 MT,和一个用来判断特征来自源域还是目标域的域辨别器 D,MT 的训练过程是最大化 D 产生错误的过程,即MT提取的特征让 D 分辨不出来是来自源域还是目标域。
目标域特征提取器 MT 和域判别器 D 互为对手:D 学习去判别特征是来自源域还是目标域,MT 学习让自己提取的特征更接近源域提取出的特征。目标域特征提取器 MT 可以被认为是一个伪造团队,试图产生假货并在不被发现的情况下使用它,而域判别器 D 类似于警察,试图检测假币。在这个游戏中的竞争驱使两个团队改进他们的方法,直到真假难分为止。
2.对抗性域适应
2.1 数据的选取
为了效果好,训练简单,我选取 mnist 数据集中 0、1 的数据作为源域,2、3 的数据作为目标域。源域和目标域的数据各 10000 个。
在训练时,源域可获得数据和标签,而目标域只能获得数据,没有标签,来模拟域适应的背景。目标域的标签仅在测试精度时使用。
2.2 网络
1.源域特征提取器 MS、目标域特征提取器 MT。所谓特征提取器,实际上就是将识别 mnist 的网络去掉最后一层分类层。
(encoder): Sequential (
(0): Conv2d(1, 32, kernel_size=(5, 5), stride=(1, 1))
(1): MaxPool2d (size=(2, 2), stride=(2, 2), dilation=(1, 1))
(2): ReLU ()
(3): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1))
(4): MaxPool2d (size=(2, 2), stride=(2, 2), dilation=(1, 1))
(5): ReLU ()
)
(fc1): Linear (64 4 4 -> 512)
把这个网络的输出看作是提取出的特征
2.分类器C。实际就是识别 mnist 的网络最后一层分类层,一个简单的全连接网络。
Classifier (
(fc2): Linear (512 -> 2)
)
3.域识别器 D。根据特征提取器的输出来判别数据来自源域还是目标域,输出 0 代表来自源域,输出 1 代表来自目标域。
Discriminator (
(layer): Sequential (
(0): Linear (512 -> 512)
(1): Linear (512 -> 512)
(2): Linear (512 -> 2)
))
3.训练过程
3.1 训练MS、C
首先,在源域上训练特征提取器 MS 和分类器 C
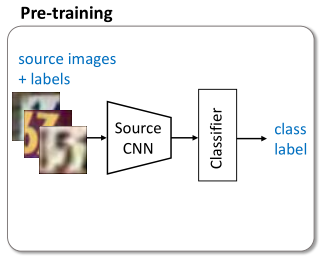

训练过程和一般训练过程相似,只不过把整个网络分成了两部分来训练、优化。
def train_MS_C(loader_ms):
# 模型
MS = Encoder()
C = Classifier()
# 优化器
o_ms = optim.SGD(MS.parameters(), lr=0.03)
o_c = optim.SGD(C.parameters(), lr=0.03)
criterion = nn.CrossEntropyLoss() # 计算损失
for j in range(1):
print(j)
# 训练
for i, (images, labels) in enumerate(loader_ms):
o_ms.zero_grad()
o_c.zero_grad()
outputs_mid = MS(images)
outputs = C(outputs_mid)
loss = criterion(outputs, labels)
loss.backward()
o_ms.step() # 优化参数
o_c.step()
if i % 100 == 0:
print(i)
print('current loss : %.5f' % loss.data.item())
# 保存模型
np.save(params.MS_save_dir, MS.get_w())
np.save(params.C_save_dir, C.get_w())
训练完成后,在源域的精确度为 0.9985
如果直接拿源域的特征提取器和分类器对目标域进行分类的话,精确度只有 0.5840
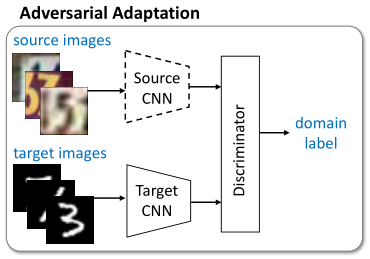
3.2 固定MS和C,训练MT和D
接着,固定 MS 和 C 不变,即不改变它们的网络权重,在源域和目标域上对抗式学习目标域特征提取器 MT 和域识别器 D
1.用 MS 初始化 MT,这样开始目标域会获得一个不错的精度 0.5840,接着在这个基础上训练,更容易收敛到好的方向,并且收敛过程也快了。
MT.update_w(np.load(params.MS_save_dir, encoding='bytes', allow_pickle=True).item())
def train_MT_D(loader_ms, loader_mt):
# 模型
MS = Encoder()
MT = Encoder()
D = Discriminator()
# 加载模型
MS.update_w(np.load(params.MS_save_dir, encoding='bytes', allow_pickle=True).item())
if params.first_train:
params.first_train = False
# 第一次训练
# MT用MS的权重初始化
MT.update_w(np.load(params.MS_save_dir, encoding='bytes', allow_pickle=True).item())
else:
MT.update_w(np.load(params.MT_save_dir, encoding='bytes', allow_pickle=True).item())
D.update_w(np.load(params.D_save_dir, encoding='bytes', allow_pickle=True).item())
# 优化器
o_mt = optim.SGD(MT.parameters(), lr=0.00001)
o_d = optim.SGD(D.parameters(), lr=0.00001)
criterion = nn.CrossEntropyLoss() # 计算损失
# 训练
for j in range(1):
print(j)
# 训练D 域辨别器
data_zip = zip(loader_ms, loader_mt)
for i, ((images_s, labels_s), (images_t, labels_t)) in enumerate(data_zip):
################对域辨别器D的训练
# 提取的特征
f_s = MS(images_s)
f_t = MT(images_t)
f_cat = torch.cat((f_s, f_t), 0)
# 域辨别器辨别结果
out_D = D(f_cat.detach())
predicts_D = torch.max(out_D.data, 1)[1]
if i == 0:
print('域辨别器的辨别结果')
print(predicts_D)
# 构造损失对比用的标签
len_s = len(labels_s)
len_t = len(labels_t)
temp1 = torch.zeros(len_s)
temp2 = torch.ones(len_t)
lab_D = torch.cat((temp1, temp2), 0).long()
# 梯度置0
o_d.zero_grad()
# 计算loss
loss_D = criterion(out_D, lab_D)
# 反向传播
loss_D.backward()
# 优化网络
o_d.step()
##################对目标域特征提取器MT的训练
# 提取的特征
f_t = MT(images_t)
# 域辨别器辨别结果
d_t = D(f_t)
# 构造计算损失的outputs、labels
out_MT = d_t
predicts_MT = torch.max(out_MT.data, 1)[1]
lab_MT = torch.zeros(len_t).long()
# 梯度置0
o_mt.zero_grad()
# 计算loss
loss_MT = criterion(out_MT, lab_MT)
# 反向传播
loss_MT.backward()
# 优化网络
o_mt.step()
if i % 100 == 0:
print(i)
print('current loss_D : %.5f' % loss_D.data.item())
print('current loss_MT : %.5f' % loss_MT.data.item())
# 保存模型
np.save(params.MT_save_dir, MT.get_w())
np.save(params.D_save_dir, D.get_w())
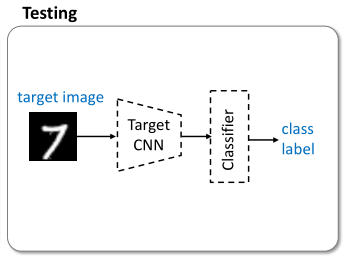
4.用MT和C在目标域上分类
最后用训练好的目标域特征提取器 MT 和分类器 C 来在目标域上分类
def test_MT_C(loader_mt):
MT = Encoder()
C = Classifier()
# 加载模型
MT.update_w(np.load(params.MT_save_dir, encoding='bytes', allow_pickle=True).item())
C.update_w(np.load(params.C_save_dir, encoding='bytes', allow_pickle=True).item())
correct = 0
for images, labels in loader_mt:
outputs_mid = MT(images)
outputs = C(outputs_mid)
_, predicts = torch.max(outputs.data, 1)
correct += (predicts == labels).sum()
total = len(loader_mt.dataset)
print('MT+C Accuracy: %.4f' % (1.0 * correct / total))
5.实验结果
拿源域的特征提取器和分类器对目标域进行分类的话,精确度只有 0.5840
下图是域辨别器 D 的结果,前半部分的输入是源域的特征,后半部分的输入是目标域的特征,现在 D 大部分都能判断正确。

训练几轮后,精确度上升了一点.

D 对域的分辨能力下降了,大部分目标域的输入都判断为源域的。
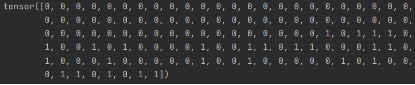
在训练 40 轮后,精确度在 0.9 附近波动,与开始的 0.5840 相比,精确度提升了很多

D 无法分辨源域和目标域了,将所有输入都识别为源域的

6.代码位置
https://momodel.cn/explore/5f1574360a2fac574eb9c3f6?type=app











评论 (0)