


作者:余敏君
1 前言
以往的联邦学习工作往往仅专注于对监督学习任务的研究,即要求所有的数据都必须包含相应的标签。但是,在现实场景中,考虑到大数据量标注任务所需要的人力和物力开销是非常大的,因此本地客户端所包含的数据常常大部分甚至全部都是没有相应标签信息的。为了解决上述问题,大量新的学习范式应运而生。这其中,半监督学习作为一种解决标签数据量小问题的有效方法,被广大机器学习研究者所偏爱。本博客将从联邦半监督学习入手,为大家介绍其相关的基本概念,并详细讲解一种争对该应用场景的相关算法——FedMatch。
2 FSSL定义及应用场景
2.1 半监督学习
半监督学习(Semi-Supervised Learning),是一种利用少量带标签数据和大量无标签数据进行模型训练的机器学习方法。一方面,考虑到根据半监督学习的定义,其可以解决带标签数据量少的现实问题;另一方面,考虑到相较于无监督学习,其仍然可以利用一部分标签信息来降低训练模型的难度,因此,对半监督学习的研究具有非常重要的现实意义。对于半监督学习的理解,有一种说法可以供大家参考:半监督学习其实就是利用大量的无标签数据来弥补少量标签数据指导模型训练所容易造成的过拟合现象(提高泛化能力)。
2.2 联邦学习
联邦学习(Federated Learning),是一种在确保本地客户端数据隐私安全的前提下,通过中心化服务器调用多方本地客户端联合训练模型的一种学习范式。联邦学习的一个非常重要的作用,就是可以在极高的隐私保护要求下,为机器学习相关任务提供大量的训练数据。联邦学习的这一特性在人们对于隐私保护日益重视的今天,对目前仍需要大量数据支撑的机器学习方法来说起着至关重要的作用。
2.3 联邦半监督学习
2.3.1 基本定义
从广义上理解,所谓联邦半监督学习(Federated Semi-Supervised Learning, FSSL),其实就是将半监督学习方法应用于联邦学习的应用场景之中,结合两种技术的优势来更好地解决现实问题。该技术一方面可以通过联邦学习保证具备充足的训练数据,另一方面又可以通过半监督学习来缓解各个客户端分散数据标注开销大的问题。按个人的理解,其主要可以分为以下两种类型:
- 第一类是在联邦学习的配置下,训练半监督学习模型
- 第二类是结合一些其他的技术,解决联邦学习中存在的某些问题/瓶颈(例如通讯瓶颈)
由于第二类方法更多的还是强调联邦学习的基本配置,因此,为了更好地对联邦半监督学习的相关内容进行介绍,本文主要针对第一类学习方法进行探讨。
2.3.2 应用场景
论文[1]根据带标签的数据集是在客户端还是在服务器端将联邦半监督应用场景划分为标准场景(standard scenario)和不相交场景(disjoint scenario)者两个类别。两种应用场景的示意图如图1所示。
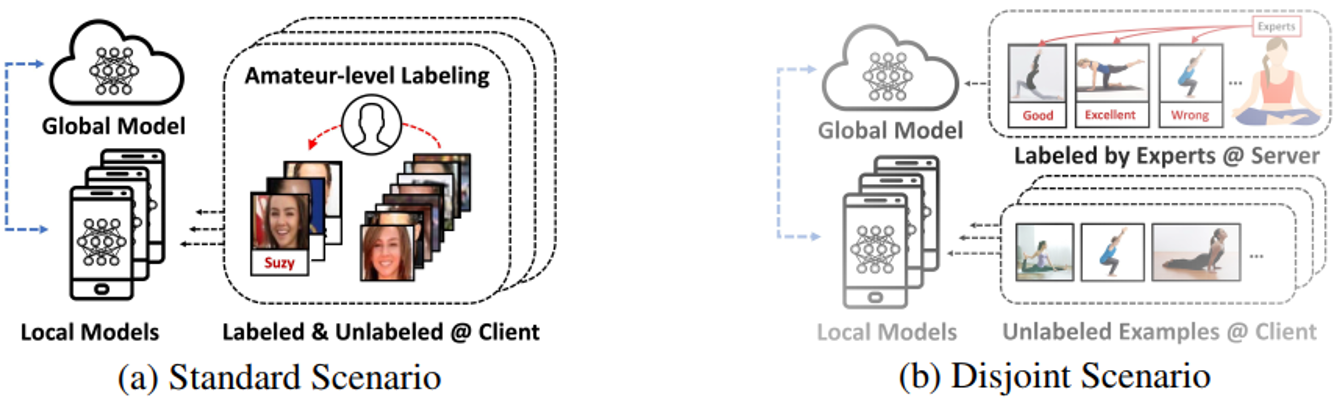
图1 联邦半监督的两种应用场景
2.3.2.1 标准场景
所谓标准场景,是指参与模型训练的带标签数据和无标签数据均存放于本地客户端,即本地执行标准的半监督学习训练。如图1(a)中的例子,对于提供给手机端客户的照片自动归类存放模型,其训练所用到的照片数据,可能会有一小部分照片已经被用户放在了指定的文件夹中(该文件夹即为标签信息),而大部分照片并未被归类(无标签信息),此时客户端的模型训练便满足半监督学习的配置。该应用场景产生的主要原因是因为服务商不可能要求每一个客户都为模型的训练去标注所有的相关数据。
2.3.2.2 不相交场景
所谓不相交场景,是指参与模型训练的带标签数据被存放在服务端中,而大量的无标签数据却存放在本地客户端中,即带标签的监督学习过程和无标签的无监督学习过程将分别在服务器端和客户端进行。该应用场景主要是由于许多数据的标注工作是需要具备相关专业知识的人员来进行处理的。例如图1(b)中的例子,对于瑜伽姿势矫正手机APP软件,由于普通人是难以确认自己的瑜伽姿势是否完成正确,因此,即使用户愿意为服务商标注所有的图片数据,服务商也只能聘请那些瑜伽专业人才来对相关数据进行标注。
博客对上述两种联邦半监督应用场景的区别进行了简单的归类,其具体内容如表1所示。
表1 两种应用场景的对比
| 标准场景 | 不相交场景 | |
|---|---|---|
| 定义 | 带标签数据和无标签数据均存放于本地 | 带标签数据存放于服务器端,无标签数据存放于本地 |
| 训练方式 | 本地执行标准的半监督模型训练 | 无标签和带标签模型训练过程完全分离(但是相关联的) |
| 符合场景 | 不可能期望各个本地客户对所有数据进行标注 | 数据的标注需要专业人士参与 |
3 FedMatch算法
针对上述两种应用场景,这篇来自于ICML workshop'2020的论文[1]提出了一种称为Federated Matching(FedMatch)的联邦半监督学习算法。对于联邦半监督学习相关的论文,个人认为需要从以下三个关注点来对其进行理解:
- 该算法适用于哪种联邦半监督应用场景(标准or不相交)
- 该算法是如何利用带标签和无标签数据的(半监督学习关注点)
- 该算法为服务器端设计了怎样的模型聚合方式(联邦学习关注点)
接下来,博客将会从这三个关注点入手,详细介绍FedMatch算法的相关内容,以此间接反映出联邦半监督算法的一般设计思路。
3.1 应用场景&核心思路
FedMatch算法通过模型的稍事修改可以应用于上述所提及的两种联邦半监督学习应用场景之中。该算法的核心设计思路主要有以下两方面内容:
- 利用最大化各客户端模型之间的共识从无标签信息中进行学习
- 通过对模型参数进行分解和隔离,以降低监督学习和无监督学习过程之间的相关影响并减少通讯开销
3.2 数据利用方式
FedMatch算法将带标签和无标签数据的模型训练分解为两个过程。对于带标签数据的训练,算法采用一般的监督学习模式,利用交叉熵损失函数来指导模型的优化。而对于无标签数据,FedMatch算法采用了一种称为一致性正则化的方法来对其进行训练。
3.2.1 一致性正则化
一致性正则化(Consistency Regularization)是一种目前比较流行的半监督学习算法,其主要是在半监督学习的配置下,从大量的无标签数据中学习到所需的相关知识。一致性正则化的核心思想其实非常简单:对于模型的一个输入,即使其受到了微小的干扰,模型对其的预测结果应该是一致的[2]。举一个简单的例子,对于一张受到较小强度噪声干扰的小狗图片,其分类模型的输出应该还是小狗而不会是一只小猫。当然所受到的干扰是在一定程度范围内的,如果干扰过大,即使是人也不一定能够将其分类正确。
一致性正则化的一种通常思路是预测器对于一个原始样例和一个其通过数据增强手段处理过的版本样例,其输出结果应该尽可能保持一致(一致性思想)。其数学表达式如下所示:
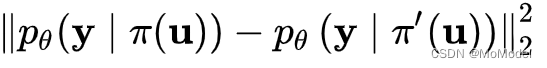
其中,函数
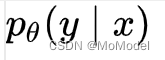
可以理解为预测x为y的概率函数。而在使用softmax函数的分类器中,该概率函数其实就是softmax的输出,即符合上述一致性思想,模型对于原始样本和增强样本的输出应该尽可能一致。此处的输出不仅仅指样本对应类别的值需要一致,对分类为其他类别的值也是需要尽可能一致的(读者可以细细评味)。论文中的FedMatch算法主要设计了两种一致性正则化算法来指导模型的训练。
3.2.1.1 Inter-client Consistency Loss
首先,FedMatch针对FSSL配置下的无标签数据设计了一种称为inter-client consistency的一致性正则化损失函数。其对应的公式如下所示:
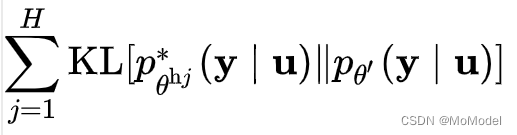
其中
是指本地模型对应于输入u的输出,
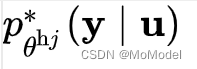
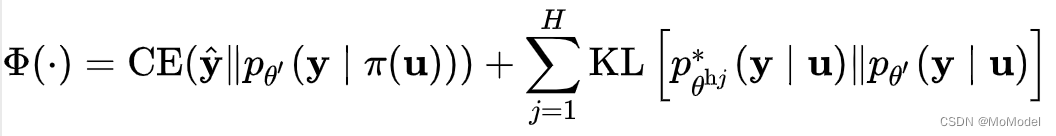
其中,CE函数部分即为data-level的一致性正则化损失函数,CE就是交叉熵函数。其中标签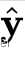
的计算公式如下所示: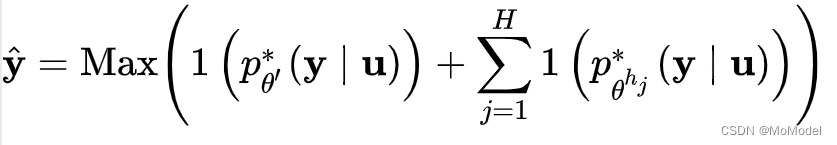 此处,
此处,
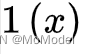
函数指one-hot化,即将模型输出中最大值对应位置(模型认为输入属于该类别)置为1,其他位置的数值置为0;
函数的作用是中输出向量中取出最大值所对应的位置,即为输出的标签。这里,最终输出的标签值有两部分决定,一部分是本地模型对于输入的输出,另一部分是helper agent模型对于指定输入的输出。
有趣的是,最终标签的输出其实是基于一种投票思想产生的:对于每一个[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gQ7r6Vz2-1606828583758)(https://cdn.nlark.com/yuque/__latex/8f5d955f41047432de23a16265207de5.svg#card=math&code=%5Cmathbb%7B1%7D%5Cleft%28x%5Cright%29&height=20&width=33)]函数,其本质上就是模型在自己认为该输入应该归属的输出的位置上投了一票。最后利用[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rkaB6Typ-1606828583758)(https://cdn.nlark.com/yuque/__latex/4b6f813759297b29e551239049f4af0d.svg#card=math&code=%5Coperatorname%7BMax%7D%5Cleft%28%5Cright%29&height=20&width=45)]函数选取投票最高的位置,即可认做该输入所属的类别/标签。其实这就体现出了一种**共识机制**。
由此,对于无标签数据,一致性正则化方法设计完毕。
3.2.2 参数分解
论文的作者通过实现发现,如果在同一个模型参数上分别进行标签数据和无标签数据的训练(即共享模型参数),无标签训练过程可能会导致模型忘记从带标签数据中学习到的知识。因此,FedMatch算法考虑将模型的参数分解为监督学习和无监督学习两个部分,通过两个部分参数的独立更新来缓解模型遗忘现象。
我们假设模型的参数θ被分解为监督学习参数σ和无监督学习参数ψ。在执行标签数据的监督学习过程时,算法将无监督参数ψ冷冻(即不执行反向传播),然后利用交叉熵损失函数指导模型进行训练,其对应的训练目标如下所示,其中
表示数据增强方法。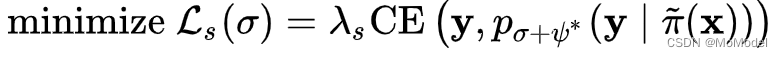
无标签数据的无监督算法过程同理可得,算法需要对监督学习参数σ进行冷冻,然后依据上一小节的一致性正则化损失函数来指导模型进行训练,其对应的训练目标表达式如下所示: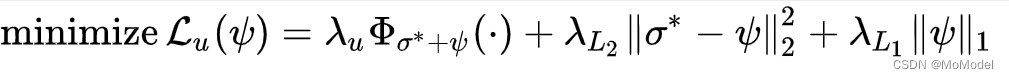
在上述公式中,FedMatch算法还为其添加了L1和L2正则项。其中L2正则项的作用是为了尽可能保留从监督学习参数σ中所学习到的知识(该部分利用L2范式尽可能使得参数σ和ψ差距越小);L1正则项的作用则是使无监督参数集合ψ尽可能包含0的项,以提高联邦学习的通讯效率(为0的参数可以不往服务器端传播)。
论文其实并未对模型参数的分解过程进行具体介绍,以下是我个人认为的一种符合其要求的参数分解方案,以供大家探讨。对于模型参数的分解,FedMatch算法应该是将神经网络模型中的每一个参数分解成为两个不同参数的和,即每个参数都分解为监督参数部分加无监督参数部分。如此操作,就可以保证监督学习和无监督学习参数在模型的每一个位置都起到相应的作用。
3.3 模型聚合方式
传统的联邦学习算法一般采用FedAvg模型所设计的聚合方法来对模型进行聚合。FedAvg所采用的模型聚合方式就是按照各个客户端所具备的数据量占总训练数据量的比例来对各个参与聚合的本地模型进行加权平均。基于此,FedMatch算法设计了一种考虑本地模型可靠性的聚合方法来对各个本地模型进行聚合。此处的可靠性指的是模型从数据中所学到知识对于解决相关任务的可靠性程度。FedMatch算法的可靠性计算公式如下所示:
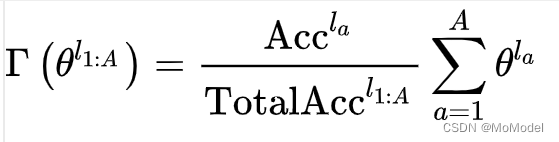
其中,
表示编号为a的客户端模型在服务器验证数据集上的分类准确度,
表示从编号1开始到编号为A的所有模型的集合。由上式可以看出,该聚合方法其实就是基于模型在公共验证集上的分类准确度来对各个模型进行加权聚合。
除此之外,在服务器端的模型可靠性计算也为之前所讲解的一致性正则化损失函数提供了helper agent的选择机制,即helper agent是每轮各个本地模型的集合中可靠性最大的H个模型的集合。此处的可靠性衡量其实就是一种各个客户端间所达成的共识机制。
3.4 算法运行流程
综上,FedMatch算法的核心内容已讲解完毕。但对于两种不同的联邦半监督应用场景,FedMatch实际的运行流程还是有些细差别的。两种应用场景的FedMatch运行流程示意图如图2所示:

图2 FedMatch在两种应用场景下的运行流程
对于标准场景,因为数据全都放置在客户端本地,因此,对于每一轮的模型训练,监督学习参数和无监督学习参数的更新都可以在本地完成。当参数更新完成后,各个客户端将会把模型的参数传送值服务器端。服务器使用模型聚合方法对各个本地模型进行聚合,并选取指定数目的helper agent。若聚合的模型性能仍为达到预期,服务器将会把聚合模型和helper agent再次传送给各个客户端。如上操作反复训练和聚合模型,直至模型的分类性能达到预期。
对于不相交场景,由于其标签数据和无标签数据被分别放置在服务器端和各个客户端,因此,监督学习和无监督学习过程也将被分开执行。服务器端将在带标签数据上训练好的模型和helper agent投入各个本地客户端中进行无监督学习的训练。模型在本地训练完毕后,客户端将会把模型权重重新传送至服务器端。服务器端对各个本地模型采用聚合方法进行聚合,并选出指定数目的helper agent。上述过程被反复操作,直至聚合模型的分类性能达到预期的值。
4 总结
从目前已经发表的论文来看,联邦半监督学习的研究仍然处于起步阶段。现有的论文基本上都是从直接应用的角度研究联邦半监督学习,而对于相关理论的研究却是十分欠缺的。个人仍为,联邦半监督学习的应用场景是非常广泛的,因此,对其进行更深一步地研究确实是有很重要的现实意义的。除了理论方向,我认为还可以从如何更有效地利用无标签数据和改进聚合算法的角度来开展联邦半监督学习的研究工作。总之,联邦半监督学习的研究仍需大量科研人员为之不断努力奋斗。
参考文献
[1] Jeong W, Yoon J, Yang E, et al. Federated semi-supervised learning with inter-client consistency[J]. arXiv preprint arXiv:2006.12097, 2020.
[2] 半监督深度学习又小结之Consistency Regularization, 糯米稻谷. https://zhuanlan.zhihu.com/p/46893709
[3] KL散度的含义与性质, 麒麟437. [https://blog.csdn.net/qq_40406773/article/details/80630280
欢迎关注我们的微信公众号:MomodelAI
同时,欢迎使用 「Mo AI编程」 微信小程序
以及登录官网,了解更多信息:Mo 平台
Mo,发现意外,创造可能













![https://cdn.nlark.com/yuque/__latex/8f5d955f41047432de23a16265207de5.svg#card=math&code=%5Cmathbb%7B1%7D%5Cleft%28x%5Cright%29&height=20&width=33)]函数,其本质上就是模型在自己认为该输入应该归属的输出的位置上投了一票。最后利用[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rkaB6Typ-1606828583758)(https://cdn.nlark.com/yuque/__latex/4b6f813759297b29e551239049f4af0d.svg#card=math&code=%5Coperatorname%7BMax%7D%5Cleft%28%5Cright%29&height=20&width=45)]函数选取投票最高的位置,即可认做该输入所属的类别/标签。其实这就体现出了一种**共识机制](https://cdn.nlark.com/yuque/__latex/8f5d955f41047432de23a16265207de5.svg#card=math&code=%5Cmathbb%7B1%7D%5Cleft%28x%5Cright%29&height=20&width=33)]函数,其本质上就是模型在自己认为该输入应该归属的输出的位置上投了一票。最后利用[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rkaB6Typ-1606828583758)(https://cdn.nlark.com/yuque/__latex/4b6f813759297b29e551239049f4af0d.svg#card=math&code=%5Coperatorname%7BMax%7D%5Cleft%28%5Cright%29&height=20&width=45)]函数选取投票最高的位置,即可认做该输入所属的类别/标签。其实这就体现出了一种**共识机制){kind=link}
评论 (0)