

作者:郑培
无监督学习是一类用于在数据中寻找模式的机器学习技术。无监督学习算法使用的输入数据都是没有标注过的,这意味着数据只给出了输入变量(自变量 X)而没有给出相应的输出变量(因变量)。在无监督学习中,算法本身将发掘数据中有趣的结构。在监督学习中,系统试图从之前给出的示例中学习。(而在无监督学习中,系统试图从给定的示例中直接找到模式。)因此,如果数据集被标注过了,这就是一个监督学习问题;而如果数据没有被标注过,这就是一个无监督学习问题。
聚类属于无监督学习,以往的回归、朴素贝叶斯、SVM等都是有类别标签y的,也就是说样例中已经给出了样例的分类。而聚类的样本中却没有给定y,只有特征x。K-means 是我们最常用的基于欧式距离的聚类算法,它是数值的、非监督的、非确定的、迭代的,该算法旨在最小化一个目标函数——误差平方函数(所有的观测点与其中心点的距离之和),其认为两个目标的距离越近,相似度越大,由于具有出色的速度和良好的可扩展性,Kmeans聚类算法算得上是最著名的聚类方法。本文将带大家回顾K-means算法的理论内涵以及初始化优化K-Means++方法。
本文的项目实例实现在Momodel平台上,可以边看边学哦!
mo平台项目地址:https://momodel.cn/workspace/5eb7e4a31089644d6a4e5c4b?type=app
1 简介
直观了解K-means算法有许多有趣的例子,其中有一个最著名的解释,即牧师—村民模型:
有四个牧师去郊区布道,一开始牧师们随意选了几个布道点,并且把这几个布道点的情况公告给了郊区所有的村民,于是每个村民到离自己家最近的布道点去听课。听课之后,大家觉得距离太远了,于是每个牧师统计了一下自己的课上所有的村民的地址,搬到了所有地址的中心地带,并且在海报上更新了自己的布道点的位置。牧师每一次移动不可能离所有人都更近,有的人发现A牧师移动以后自己还不如去B牧师处听课更近,于是每个村民又去了离自己最近的布道点…… 就这样,牧师每个礼拜更新自己的位置,村民根据自己的情况选择布道点,最终稳定了下来。
我们可以看到该牧师的目的是为了让每个村民到其最近中心点的距离和最小。在实际生活中,许多数据的聚类可以通过观察得出,但是如何让计算机找出聚类的点群就需要像K-means这类的算法帮助。
图一 K-means目标
在聚类问题中,给我们的训练样本是 $ \left{x^{(1)}, \ldots, x^{(m)}\right}, \quad x^{(i)} \in \mathbb{R}^{n} $,K-means算法是将样本聚类成$k$个簇(cluster),具体算法描述如下:
- 随机选取$k$个聚类质心点(cluster centroids)为$\mu{1}, \mu{2}, \ldots, \mu{k} \in \mathbb{R}^{n}$
- 重复下面过程直到收敛:
- 对于每一个样例i,计算其应该属于的类:$c^{(i)}:=\arg \min {j}\left|x^{(i)}-\mu{j}\right|^{2}$
- 对于每一个类j,重新计算该类的质心:$\mu{j}:=\frac{\sum{i=1}^{m} 1\left{c^{(i)}=j\right} x^{(i)}}{\sum_{i=1}^{m} 1\left{c^{(i)}=j\right}}$
K是我们事先给定的聚类数,$c^{(i)}$ 距离最近的那个类,$c^{(i)}$的值是1到k中的一个。质心 $\mu{j}$ 代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团作为 $c^{(i)}$,这样经过第一步每一个星星都有了所属的星团;第二步对于每一个星团,重新计算它的质心 $\mu{j}$(对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。
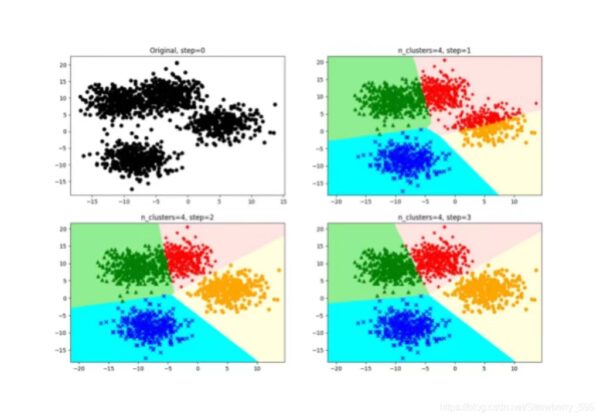
下图展示了对n个样本点进行K-means聚类的效果,这里k取2。
K-means面对的第一个问题是如何保证收敛,前面的算法中强调结束条件就是收敛,可以证明的是K-means完全可以保证收敛性。下面我们定性的描述一下收敛性,我们定义畸变函数(distortion function)如下:
$$J(c, \mu)=\sum{i=1}^{m}\left|x^{(i)}-\mu{c^{(i)}}\right|^{2}$$
$J$函数表示每个样本点到其质心的距离平方和。K-means是要将J调整到最小。假设当前J没有达到最小值,那么首先可以固定每个类的质心$\mu{j}$,调整每个样例的所属的类别 $c^{(i)}$ 来让J函数减少。同样,固定$c^{(i)}$,调整每个类的质心$\mu{j}$也可以使J减小。这两个过程就是内循环中使J单调递减的过程。当J递减到最小时,$\mu$和$c$也同时收敛。(在理论上,可以有多组不同的$\mu$和$c$值能够使得J取得最小值,但这种现象实际上很少见)。
由于畸变函数J是非凸函数,意味着我们不能保证取得的最小值是全局最小值,也就是说k-means对质心初始位置的选取比较感冒,但一般情况下k-means达到的局部最优已经满足需求。但如果你怕陷入局部最优,那么可以选取不同的初始值跑多遍k-means,然后取其中最小的J对应的$\mu$和$c$输出。
2 K-means 细节与调优
K-means 算法具有很多优点,例如:聚类效果良好,局部最优在很多情况能够满足需求;在处理大数据集时,可以保证较好的伸缩性;算法复杂度低;当簇近似高斯分布的时候,效果优良。但是K-Means主要有两个最重大的缺陷——都和初始值有关:
- K 是事先给定的,这个 K 值的选定是非常难以估计的。很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。
- K-Means算法需要用初始随机种子点来计算,这个随机种子点太重要,不同的随机种子点会有得到完全不同的结果。
2.1 K值选取
K 值的选取对 K-means 影响很大,这也是 K-means 最大的缺点,常见的选取 K 值的方法有:手肘法、Gap statistic 方法。
如果我们拿到的样本,客观存在J个“自然小类”,这些真实存在的小类是隐藏于数据中的。三维以下的数据我们还能画图肉眼分辨一下J的大概数目,更高维的就不能直观地看到了,我们只能从一个比较小的K,譬如K=2开始尝试,去逼近这个真实值$J$。
- 当K小于样本真实簇数J时,K每增大一个单位,就会大幅增加每个簇的聚合程度,这时距离和的下降幅度会很大;
- 当K接近J时,再增加K所得到的聚合程度回报会迅速变小,距离和的下降幅度也会减小;
- 随着K的继续增大,距离和的变化会趋于平缓。
例如下图,真实的J我们事先不知道,那么从K=2开始尝试,发现K=3时,距离和大幅下降,K=4时,下降幅度急速缩水,再后面就越来越平缓。所以我们认为J应该为3,因此可以将K设定为3。
手肘法的缺点在于需要人工看不够自动化,所以我们又有了 Gap statistic 方法,这个方法出自斯坦福大学的几个学者的论文:Estimating the number of clusters in a data set via the gap statistic, 对应公式如下:
$$\operatorname{Gap}(K)=\mathrm{E}\left(\log D{k}\right)-\log D{k}$$
其中 $D{k}$ 为损失函数,这里 $E\left(\log D{k}\right)$ 指的是 $\log D{k}$ 的期望。这个数值通常通过蒙特卡洛模拟产生,我们在样本里所在的区域中按照均匀分布随机产生和原始样本数一样多的随机样本,并对这个随机样本做 K-Means,从而得到一个 $D{k}$。如此往复多次,通常 20 次,我们可以得到 20 个 $\log D{k}$。对这 20 个数值求平均值,就得到了 $E\left(\log D{k}\right)$ 的近似值。最终可以计算 Gap Statisitc。而 Gap statistic 取得最大值所对应的 K 就是最佳的 K。
由图可见,当 K=3 时,Gap(K) 取值最大,所以最佳的簇数是 K=3。
2.2 K-means++
在上文中我们提到,k个初始化的质心的位置选择对最后的聚类结果和运行时间都有很大的影响,因此需要选择合适的k个质心。如果仅仅是完全随机的选择,有可能导致算法收敛很慢。K-Means++算法就是对K-Means随机初始化质心的方法的优化。K-Means++的对于初始化质心的优化策略也很简单,如下:
1) 从输入的数据点集合中随机选择一个点作为第一个聚类中心$μ_1$
2) 对于数据集中的每一个点$x_i$,计算它与已选择的聚类中心中最近聚类中心的距离:$D(X_i)=arg\; min||x_i-μ_r||^2_2 \qquad r=1,2……k_selected$
3) 选择一个新的数据点作为新的聚类中心,选择的原则是:$D(x)$较大的点,被选取作为聚类中心的概率较大
4) 重复2和3直到选择出k个聚类质心
5) 利用这k个质心来作为初始化质心去运行标准的K-Means算法
简单的来说,就是 K-means++ 就是选择离已选中心点最远的点。这也比较符合常理,聚类中心当然是互相离得越远越好。
3 K-means算法应用
看到这里,你会说,K-Means算法看来很简单,而且好像就是在玩坐标点,没什么真实用处。而且,这个算法缺陷很多,还不如人工呢。是的,前面的例子只是玩二维坐标点,的确没什么意思。但是你想一下下面的几个问题:
1) 不是二维的,是多维的,如5维的,那么,就只能用计算机来计算了。
2) 坐标点的X, Y 坐标,其实是一种向量,是一种数学抽象。现实世界中很多属性是可以抽象成向量的,比如,我们的年龄,我们的喜好,我们的商品,等等,能抽象成向量的目的就是可以让计算机知道某两个属性间的距离。如:我们认为,18岁的人离24岁的人的距离要比离12岁的距离要近,鞋子这个商品离衣服这个商品的距离要比电脑要近,等等。只要能把现实世界的物体的属性抽象成向量,就可以用K-Means算法来归类了。
mo平台项目地址:https://momodel.cn/workspace/5eb7e4a31089644d6a4e5c4b?type=app
参考文献:
[1]https://ww2.mathworks.cn/help/stats/kmeans.html
[2]https://en.wikipedia.org/wiki/K-means%2B%2B
[3]https://github.com/Anfany/Machine-Learning-for-Beginner-by-Python3/tree/master/Kmeans%20Cluster













评论 (0)