

1.复杂网络基础知识
当我们拿起手机给家人、朋友或者同事拨打电话时,就不知不觉中参与到了社交网络形成的过程中;当我们登上高铁或者飞机时,就可以享受交通网络给我们带来的方便;即使当我们躺在床上什么也不干时,大脑中的神经元们也会形成巨大的复杂网络相互传递信号,帮助我们思考或者行动。复杂网络是将现实世界中各种大型复杂系统抽象成网络来进行研究的一种理论工具,在自然界中存在的大量复杂系统都可以通过形形色色的网络加以描述。
1.1 网络的表示方法
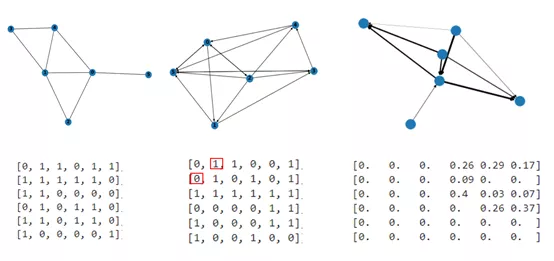
一个典型的网络是由许多节点与节点之间的连边组成,其中节点用来代表真实系统中不同的个体,而边则用来表示节点之间的关系,往往是两个节点之间存在某种特定的关系则连一条边,反之则无连接,边相连的两个节点在网络中被看作是相邻的。为了方便计算,我们通常使用邻接矩阵来表示网络。根据网络的边的类型不同,可以将网络分为无权无向网络、有向网络、含权网络,对应的邻接矩阵表示如下:
1.2 网络的统计特征
度:与节点直接相连的边数;在有向网络中可以分为出度和入度。
聚集系数:节点的邻居间互为邻居的可能,衡量的是网络的集团化程度
我们对所计算出的聚集系数求算术平均数,可以得到平均聚集系数,并以此来衡量整个网络的聚集程度。
最短路径:两个节点相连的最短连通路径
介数:介数包括节点介数和边介数。
节点介数指网络中所有最短路径中经过该节点的数量比例
边介数则指网络中所有最短路径中经过该边的数量比例
介数反映了相应的节点或者边在整个网络中的作用和影响力
1.3 常见的复杂网络模型
常用的网络模型分为规则网络、随机网络、小世界网络、无标度网络四类。
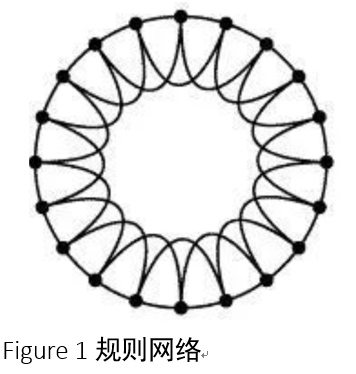
· 规则网络
规则网络是最简单的网络模型。在这种类型的网络中,任意两个节点之间的连接遵循既定的规则,通常每个节点的近邻数目都相同。
· 随机网络
节点之间是否产生连边是完全随机的。
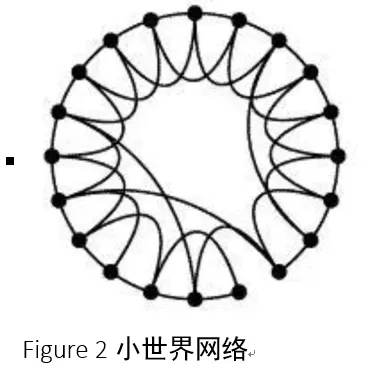
· 小世界网络
小世界网络模型是由瓦茨和斯特罗加茨在1998年《自然》上发表的《小世界网络的集体动力学》一文中提出的。他们发现,规则网络的群聚性较高,但网络之平均距离也大;而随机网络的平均距离较短,其群聚性也低。真实世界的网络既非完全规则,也非完全随机,而是介于这两者之间,于是有学者引入了小世界网络模型。
· 无标度网络
无标度网络是在网络中的大部分节点(小度节点)只和很少节点连接,而有极少的节点与(大度节点)非常多的节点连接。

基于复杂网络实现推荐系统的背景介绍
链路预测是指如何通过已知的网络结构等信息,预测网络中尚未产生连边的两个节点之间产生连接的可能性。预测那些已经存在但尚未被发现的连接实际上是一种数据挖掘的过程,而对于未来可能产生的连边的预测则与网络的演化相关。链路预测可以应用在电商网站中。如果将电商网站中的商品看成一类节点,用户看成另一类节点,如果用户A购买了商品b,A与b之间则形成一条连边,这种边只在不同类型的节点间存在的网络成为二分网络,而在二分网络中的链路预测问题其实也是推荐系统的一种。

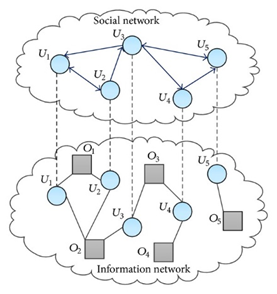
下面我们来简单介绍一个基于复杂网络的做推荐系统的文章《Information Filtering via Biased Random Walk on Coupled Social Network》。文章通过将用户的社交网络和用户——商品二分图网络进行耦合,综合了用户的社交信息与商品偏好信息对用户进行商品推荐。耦合社交网络(CSN)包含耦合节点(用户),其在社交网络层中形成领导者——跟随者关系和信息网络层中的收藏关系。下图是一个简单的耦合社交网络示意图,圆圈表示用户,方块表示对象。上半部分是五个用户的社交关系网络,U4指向U5的连边表示,U4是U5的追随者,他俩之间存在一定程度的相似性。下半部分是一个二分网络,对象O5与用户U5之间存在连边,表示用户U5收藏了O5 。若只有下半部分网络,我们无法将商品O5推荐给用户U4,当我们将社交网络中U4与U5之间的相似性考虑进来后,我们可以将对象O5推荐给用户U4。接下来,我们来具体解释该方法如何在推荐系统中发挥作用。
3. 模型介绍
对一个推荐系统,我们将其分成两个部分,用户集 U=U1,U2,…,Um 和对象集O=O1,O2,…,On,表示有m个用户和n个对象。定义邻接矩阵Am∗n来表示该网络,

邻接矩阵(B_{m*n})来表示用户——对象二分图,

3.1 社交网络上的随机游走
· P′ij是社交网络上的转移概率,从用户Ui游走到用户Uj:
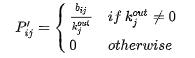
· (S_i'(t))表示在t时刻其他用户游走到用户(U_i)的概率,
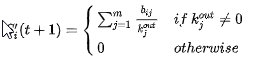
· 初始概率
对于目标用户Ui,S′i(0)=1
对于其他用户Uj,S′j(0)=1
#社交网络上的游走
#输入用户ID,概率prob,文中lama,游走步长step
user_id = '23298'
prob = 1
step = 3
# def social_network_walk(user_id, prob, step):
user_group = trust_df.groupby(trust_df[0])
#第一步游走
id_neighbors = list(user_group.get_group(user_id)[1].values)
user_prob_dic = {}
for user_id in id_neighbors:
user_prob_dic[user_id] = prob/len(id_neighbors)
user_dict = user_prob_dic.copy()
#之后的游走
for _ in range(step-2):
for item in user_dict.items():
uesr_id = item[0]
prob = item[1]
id_neighbors = list(user_group.get_group(user_id)[1].values)
for user_id in id_neighbors:
try:
user_prob_dic[user_id] += prob/len(id_neighbors)
except KeyError:
user_prob_dic[user_id] = prob/len(id_neighbors)
user_dict = user_prob_dic.copy()
# return user_dict
user_dict3.2 二分图上的随机游走
用户到商品的转移概率:
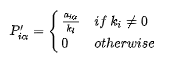
商品到用户的转移概率:

定义 S′′α(t) 和 S′′j(t) 为二部图中商品 α 和用户 t 在时刻的概率:
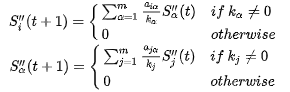
当t为奇数且 t≥3 时, S′′α(t) 表示用户 Ui(初始值设为1的用户)选择未收藏商品Oα的概率。
#在二部图网络上的游走
#第一步游走,从用户到商品
# def bipartite_walk(user_id, perct):
user_id = '23298'
prob = 1
objection_group = ratings_df.groupby(ratings_df[0]) #以用户未依据,对对象进行分类,同一个用户收藏的对象
user_group = ratings_df.groupby(ratings_df[1]) #以对象为依据,对用户进行分类,以对象为依据,同一对象被哪些用户收藏
objection_dict = {}
user_dict = {}
#第一步用户到对象
user_neighbors = objection_group.get_group(user_id)[1].values #用户的邻居是对象
for objection_id in user_neighbors:
print(objection_id)
objection_dict[objection_id] = prob/len(user_neighbors)
# #第二步对象到用户
# objection_lis = objection_dict.keys()
for item in objection_dict.items():
objection_id = item[0]
prob = item[1]
objection_neighbors = user_group.get_group(objection_id)[0].values
for user_id in objection_neighbors:
try:
user_dict[user_id] += prob/len(objection_neighbors)
except KeyError:
user_dict[user_id] = prob/len(objection_neighbors)
# #
# #第三步,用户到对象
for item in user_dict.items():
user_id = item[0]
prob = item[1]
user_neighbor = list(objection_group.get_group(user_id)[1].values)
for obj_id in user_neighbor:
try:
objection_dict[obj_id] += prob/len(user_neighbor)
except KeyError:
objection_dict[obj_id] = prob/len(user_neighbor)
objection_dict
3.3 耦合社交网络上的有偏随机游走
耦合网络中,从社交网络中用户与二分图网络中商品游走到二分图网络中的用户
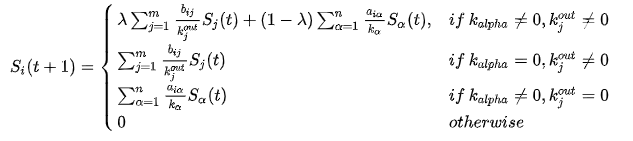
· 初始概率:
对于目标用户Ui,S′i‘(0)=1
对于其他用户U和商品α,Sj(α)=0,Sα=0
当 t 为奇数,且 t≥3 时,S′α‘(t)表示用户 Ui 选择未收藏商品 Oα 的概率(设定目标用户的初始值为1单位资源,t=1 时,资源从目标用户游走到与目标用户相邻对象;t=2 时,资源从对象再次游走到用户)。
#耦合网络游走,用户23298在耦合网络随机游走,步长为三,转移概率0.7
user_id = '23298'
prob_social = 0.7
step = 3
prob_bi = 1-prob_social
social_user_group = trust_df.groupby(trust_df[0])
#以用户未依据,对对象进行分类,同一个用户收藏的对象
bi_objection_group = ratings_df.groupby(ratings_df[0])
#以对象为依据,对用户进行分类,以对象为依据,同一对象被哪些用户收藏
bi_user_group = ratings_df.groupby(ratings_df[1])
objection_dict = {}
user_dict = {}
#第一步用户到对象
user_neighbors = bi_objection_group.get_group(user_id)[1].values #用户的邻居是对象
for objection_id in user_neighbors:
objection_dict[objection_id] = prob_social/len(user_neighbors)
for _ in range(int((step-1)/2)) :
#第二步,对象到用户
for item in objection_dict.items():
objection_id = item[0]
prob = item[1]
objection_neighbors = bi_user_group.get_group(objection_id)[0].values
for user_id in objection_neighbors:
try:
user_dict[user_id] += prob/len(objection_neighbors)
except KeyError:
user_dict[user_id] = prob/len(objection_neighbors)
user_neighbors = list(social_user_group.get_group(user_id)[1].values)
for user_id in user_neighbors:
try:
user_dict[user_id] += prob_social/len(user_neighbors)
except KeyError:
user_dict[user_id] = prob_social/len(user_neighbors)
# #第三步,用户到对象
for item in user_dict.items():
user_id = item[0]
prob = item[1]
user_neighbor = list(objection_group.get_group(user_id)[1].values)
for obj_id in user_neighbor:
try:
objection_dict[obj_id] += prob/len(user_neighbor)
except KeyError:
objection_dict[obj_id] = prob/len(user_neighbor)
objection_dict· 评价指标:
Precision 精确度,用户选择的商品在推荐列表中的比例。
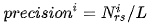
Nirs:对用户 Ui 推荐的商品出现在测试集中的数量,Lh:推荐列表的长度。
Recall 召回率,推荐的商品在用户收藏列表中的比例。
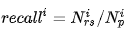
Nip:用户 Ui 在测试集中收藏的商品数量
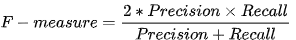
HD 汉明距离,衡量用户推荐列表的多样性。是用户 (i) 与用户 (j) 的推荐列表中具有相同商品的数量。
衡量用户对推荐列表的满意度,
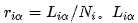
是用户未收藏的商品 α 在用户 i 推荐列表中的位置。Ni 是推荐列表的长度。
4. 结果分析
4.1 数据描述
Epinions与Friendfeed两个公开数据集均包含一个社交关系数据集和一个评分数据集。下表对数据集对应的网络进行描述。以Epinions为例,文章中随机抽取一部分数据进行分析,采样数据规模为:4066个用户,7649个对象,用户与对象连边(收藏)数量为154122条,社交网络连边数为217017。网络密度为5x10−3。

Table 1: Properties of the tested data sets
4.2 参数 λ 与 t 对实验结果的影响
λ为资源在社交网络与二分图网络中的分配比例,t 为游走步长,下图使用排序的分进行衡量,值颜色越偏冷色表示效果越好,图中可以看出在 t=3 时,预测效果较好。 当 λ=0 时,预测效果仅依赖于二分图网络,随着 λ 增加,社交网络的信息被逐渐考虑进来。
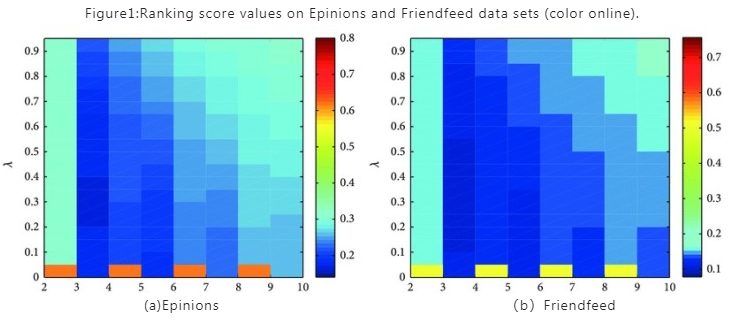
4.3 预测效果
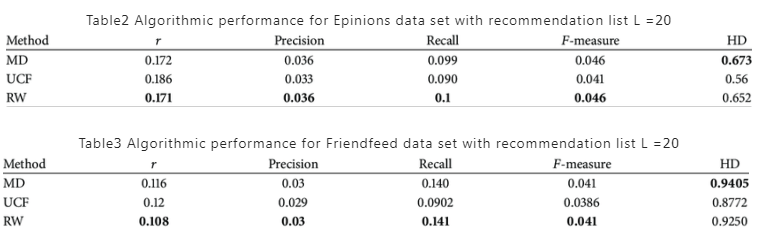
下表展示了预测长度 (L = 20) 时,该模型与 MD(mass diffusion) 模型和 UCF(user-based CF) 模型的效果比较。
本项目已在mo平台实现,记得来fork呀:https://momodel.cn/explore/5d70809e85fab71bf10a556a?type=app
关于我们
Mo(网址:https://momodel.cn)是一个支持 Python 的人工智能在线建模平台,能帮助你快速开发、训练并部署模型。
Mo 人工智能俱乐部 是由网站的研发与产品设计团队发起、致力于降低人工智能开发与使用门槛的俱乐部。团队具备大数据处理分析、可视化与数据建模经验,已承担多领域智能项目,具备从底层到前端的全线设计开发能力。主要研究方向为大数据管理分析与人工智能技术,并以此来促进数据驱动的科学研究。
目前俱乐部每两周在杭州举办线下论文分享与学术交流。希望能汇聚来自各行各业对人工智能感兴趣的朋友,不断交流共同成长,推动人工智能民主化、应用普及化。













评论 (0)