


介绍
在不断发展的技术环境中,我们发现自己正处于数据存储和检索领域突破性革命的风口浪尖。想象一下这样一个世界:应用程序可以以闪电般的速度处理大量信息,以无与伦比的效率轻松搜索和分析数据。这就是矢量数据库的承诺,这是一项尖端技术,正在重新定义我们与数据交互的方式。在本文中,我们将探讨矢量数据库的世界及其令人难以置信的潜力,特别关注它们在创建低延迟机器 (LLMs) 应用程序中的作用。加入我们!作为尖端技术和创新应用程序开发的复杂融合,以解锁使用矢量数据库构建 LLMs 应用程序的秘密。准备好颠覆数据利用方式,因为我们即将揭示解锁数据驱动应用未来的关键!

例如,如果您向亚马逊客户服务应用程序询问“如何在 Android 应用程序中更改我的语言?”,则它可能没有经过此确切文本的训练,因此可能无法回答。这就是矢量数据库的用武之地。矢量数据库将域文本(在本例中为帮助文档)和所有用户过去的查询(包括订单历史记录等)存储为数字嵌入,并实时提供相似向量的查找。在这种情况下,它将此查询编码为数值向量,并使用它来在其向量数据库中执行相似性搜索并查找其最近的邻居。借助此帮助,聊天机器人可以正确引导用户进入亚马逊应用程序上的“更改语言首选项”部分。
什么是 LLMs ?
大型语言模型 (LLMs) 是使用深度学习算法来处理和理解自然语言的基础机器学习模型。这些模型在大量文本数据上进行训练,以学习语言中的模式和实体关系。LLMs 可以执行多种类型的语言任务,例如翻译语言、分析情绪、聊天机器人对话等。他们可以理解复杂的文本数据,识别实体和它们之间的关系,并生成连贯且语法准确的新文本。
LLMs 如何工作?
LLMs 使用大量数据进行训练,通常是 TB,甚至 PB,具有数十亿或数万亿个参数,使它们能够根据用户的提示或查询预测和生成相关响应。它们通过词嵌入、自我注意层和前馈网络处理输入数据,以生成有意义的文本。您可以在此处阅读有关 LLMs 架构的更多信息。
LLMs 的局限性
虽然 LLMs 似乎以相当高的准确度生成响应,在许多标准化测试中甚至比人类更好,但这些模型仍然存在局限性。首先,他们完全依靠他们的训练数据来建立他们的推理,因此数据中可能缺乏特定或当前的信息。这导致模型产生不正确或不寻常的反应,即“幻觉”。目前正在努力缓解这种情况。其次,模型的行为或响应方式可能不符合用户的期望。
为了解决这个问题,矢量数据库和嵌入模型通过对用户正在寻找信息的类似模式(文本、图像、视频等)提供额外的查找来增强对 LLMs /生成人工智能的知识。下面是一个示例,其中 LLMs 没有用户要求的响应,而是依靠向量数据库来查找该信息。
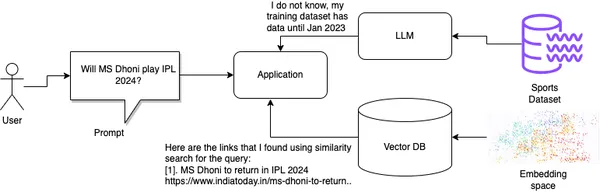
LLMs 和矢量数据库
大型语言模型 (LLMs) 正在行业的许多部分使用或集成,例如电子商务、旅游、搜索、内容创建和金融。这些模型依赖于一种相对较新的数据库类型,称为矢量数据库,它将文本、图像、视频和其他数据的数字表示存储在称为嵌入的二进制表示形式中。本节重点介绍矢量数据库和嵌入的基础知识,更重要的是,重点介绍如何使用它们与 LLMs 应用程序集成。
向量数据库是使用高维空间存储和搜索嵌入的数据库。这些向量是数据要素或属性的数值表示。使用计算高维空间中向量之间的距离或相似性的算法,向量数据库可以快速有效地检索相似数据。与将数据存储在行或列中并使用精确匹配或基于关键字的搜索方法的传统基于标量的数据库不同,矢量数据库的操作方式不同。他们使用矢量数据库,使用近似最近邻(ANN)等技术在很短的时间内(毫秒级)搜索和比较大量矢量。
关于嵌入的快速教程
AI 模型通过将文本、视频、图像等原始数据输入到矢量嵌入库(如 word2vec 和 在 AI 和机器学习的背景下,这些功能表示数据的不同维度,这对于理解模式关系和底层结构至关重要。
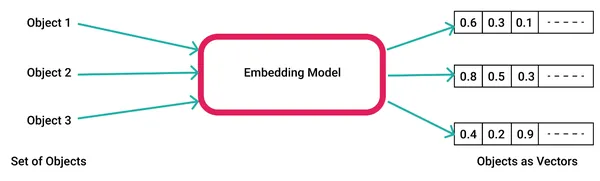
下面是如何使用 word2vec 生成单词嵌入的示例。
- 使用自定义数据语料库生成模型,或使用来自 Google 或 FastText 的示例预构建模型。如果您生成自己的文件,则可以将其作为“word2vec.model”文件保存到文件系统中。
import gensim
# Create a word2vec model
model = gensim.models.Word2Vec(corpus)
# Save the model file
model.save('word2vec.model')- 加载模型,为输入词生成向量嵌入,并使用它来获取向量嵌入空间中的相似词。
import gensim import numpy as np
Load the word2vec model
model = gensim.models.Word2Vec.load(!!039;word2vec.model!_!_039;)
Get the vector for the word "king"
kingvector = model[!_!039;king!_!_039;]
Get the most similar vectors to the king vector
similar_vectors = model.similar_by_vector(king_vector, topn=5)
Print the most similar vectors
for vector in similar_vectors:
print(vector[0], vector[1])
3.以下是接近输入单词的前 5 个单词。Output:
man 0.85
prince 0.78
queen 0.75
lord 0.74
emperor 0.72
# **LLMs 应用架构**
在高级别上,向量数据库依赖于嵌入模型来处理嵌入的创建和查询。在摄取路径上,语料库内容使用嵌入模型编码为向量,并存储在 Pinecone,ChromaDB,Weaviate 等向量数据库中。在读取路径上,应用程序使用句子或单词进行查询,然后由嵌入模型再次将其编码到向量中,然后将其查询到向量数据库中以获取结果。
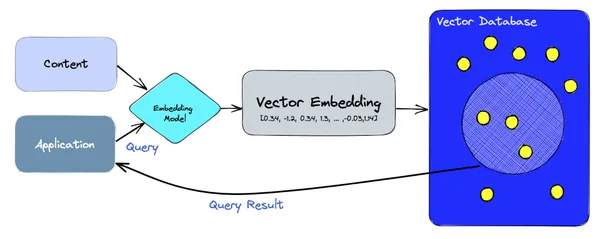
# **使用矢量数据库的 LLMs 应用程序**
LLMs 有助于语言任务,并嵌入到更广泛的模型类别中,例如生成 AI,它可以生成图像和视频,而不仅仅是文本。在本节中,我们将学习如何使用矢量数据库构建实用的 LLMs /生成式 AI 应用程序。我使用变压器和火炬库作为语言模型,松果作为矢量数据库。您可以为 LLMs /嵌入选择任何语言模型,并为存储和搜索选择任何矢量数据库。
# **构建聊天机器人应用程序**
要使用矢量数据库构建聊天机器人,您可以按照以下步骤操作:
1. 选择一个矢量数据库,如Pinecone,Chroma,Weaviate,AWS Kendra 等。
2. 为您的聊天机器人创建矢量索引。
3. 使用您选择的大型文本语料库训练语言模型。例如,对于新闻聊天机器人,您可以输入新闻数据。
4. 集成矢量数据库和语言模型。
下面是一个使用矢量数据库和语言模型的聊天机器人应用程序的简单示例:
import pinecone
import transformers
Create an API client for the vector database
client = pinecone.Client(api_key="YOUR_API_KEY")
Load the language model
model = transformers.AutoModelForCausalLM.from_pretrained("google/bigbird-roberta-base")
Define a function to generate text
def generate_text(prompt):
inputs = model.prepare_inputs_for_generation(prompt, return_tensors="pt")
outputs = model.generate(inputs, max_length=100)
return outputs[0].decode("utf-8")
Define a function to retrieve the most similar vectors to the user!!_039;s query vector
def retrieve_similar_vectors(query_vector):
results = client.search("my_index", query_vector)
return results
Define a function to generate a response to the user!!_039;s query
def generate_response(query):
Retrieve the most similar vectors to the user!!_039;s query vector
similar_vectors = retrieve_similar_vectors(query)
# Generate text based on the retrieved vectors
response = generate_text(similar_vectors[0])
return responseStart the chatbot
while True:
Get the user!!_039;s query
query = input("What is your question? ")
# Generate a response to the user's query
response = generate_response(query)
# Print the response
print(response)
此聊天机器人应用程序将从向量数据库中检索与用户的查询向量最相似的向量,然后使用基于检索到的向量的语言模型生成文本。
ChatBot > What is your question?
User_A> How tall is the Eiffel Tower?
ChatBot>The height of the Eiffel Tower measures 324 meters (1,063 feet)
from its base to the top of its antenna.
# **构建图像生成器应用程序**
让我们探索如何构建同时使用生成式 AI 和 LLMs 库的图像生成器应用程序。
1. 创建矢量数据库以存储图像矢量。
2. 从训练数据中提取图像向量。
3. 将图像矢量插入到矢量数据库中。
4. 训练生成对抗网络 (GAN)。
5. 集成矢量数据库和 GAN。
下面是一个集成矢量数据库和 GAN 以生成图像的程序的简单示例:
import pinecone
import torch
from torchvision import transforms
Create an API client for the vector database
client = pinecone.Client(api_key="YOUR_API_KEY")
Load the GAN
generator = torch.load("generator.pt")
Define a function to generate an image from a vector
def generate_image(vector):
Convert the vector to a tensor
tensor = torch.from_numpy(vector).float()
# Generate the image
image = generator(tensor)
# Transform the image to a PIL image
image = transforms.ToPILImage()(image)
return imageStart the image generator
while True:
Get the user!!_039;s query
query = input("What kind of image would you like to generate? ")
# Retrieve the most similar vector to the user's query vector
similar_vectors = client.search("my_index", query)
# Generate an image from the retrieved vector
image = generate_image(similar_vectors[0])
# Display the image
image.show()该程序将从向量数据库中检索与用户查询向量最相似的向量,然后根据检索到的向量使用 GAN 生成图像。
ImageBot>What kind of image would you like to generate?
Me>An idyllic image of a mountain with a flowing river.
ImageBot> Wait a minute! Here you go...

*生成的图像*
您可以自定义此程序以满足您的特定需求。例如,您可以训练专门用于生成特定类型的图像(例如肖像或风景)的 GAN。
# **构建电影推荐应用**
让我们探讨一下如何从电影语料库构建电影推荐应用。您可以使用类似的想法为产品或其他实体构建推荐系统。
1. 创建矢量数据库以存储电影矢量。
2. 从电影元数据中提取电影矢量。
3. 将电影矢量插入矢量数据库。
4. 向用户推荐电影。
下面是如何使用松果 API 向用户推荐电影的示例:
import pinecone
Create an API client
client = pinecone.Client(api_key="YOUR_API_KEY")
Get the user!!_039;s vector
user_vector = client.get_vector("user_index", user_id)
Recommend movies to the user
results = client.search("movie_index", user_vector)
Print the results
for result in results:
print(result["title"])
下面是对用户的示例建议
The Shawshank Redemption
The Dark Knight
Inception
The Godfather
Pulp Fiction
# **使用矢量搜索/数据库的 LLMs 的真实用例**
● Microsoft 和 TikTok 使用 Pinecone 等矢量数据库进行长期记忆和更快的查找。如果没有矢量数据库,LLMs 就无法单独完成。它正在帮助用户保存他们过去的问题/回答并恢复他们的会话。例如,用户可以问:“告诉我更多关于我们上周讨论的意大利面食谱。
● Flipkart 的决策助手通过首先将查询编码为向量嵌入,然后对在高维空间中存储相关产品的向量进行查找,向用户推荐产品。例如,如果您搜索“牧马人皮夹克棕色男士中号”,则它使用矢量相似性搜索向用户推荐相关产品。否则,LLMs 将没有任何建议,因为没有产品目录将包含此类标题或产品详细信息。你可以在这里阅读。
● 非洲的金融科技公司 Chipper Cash 使用矢量数据库将欺诈用户注册量减少了 10 倍。它通过将以前用户注册的所有图像存储为矢量嵌入来实现这一点。然后,当新用户注册时,它会将其编码为向量,并将其与现有用户进行比较以检测欺诈行为。
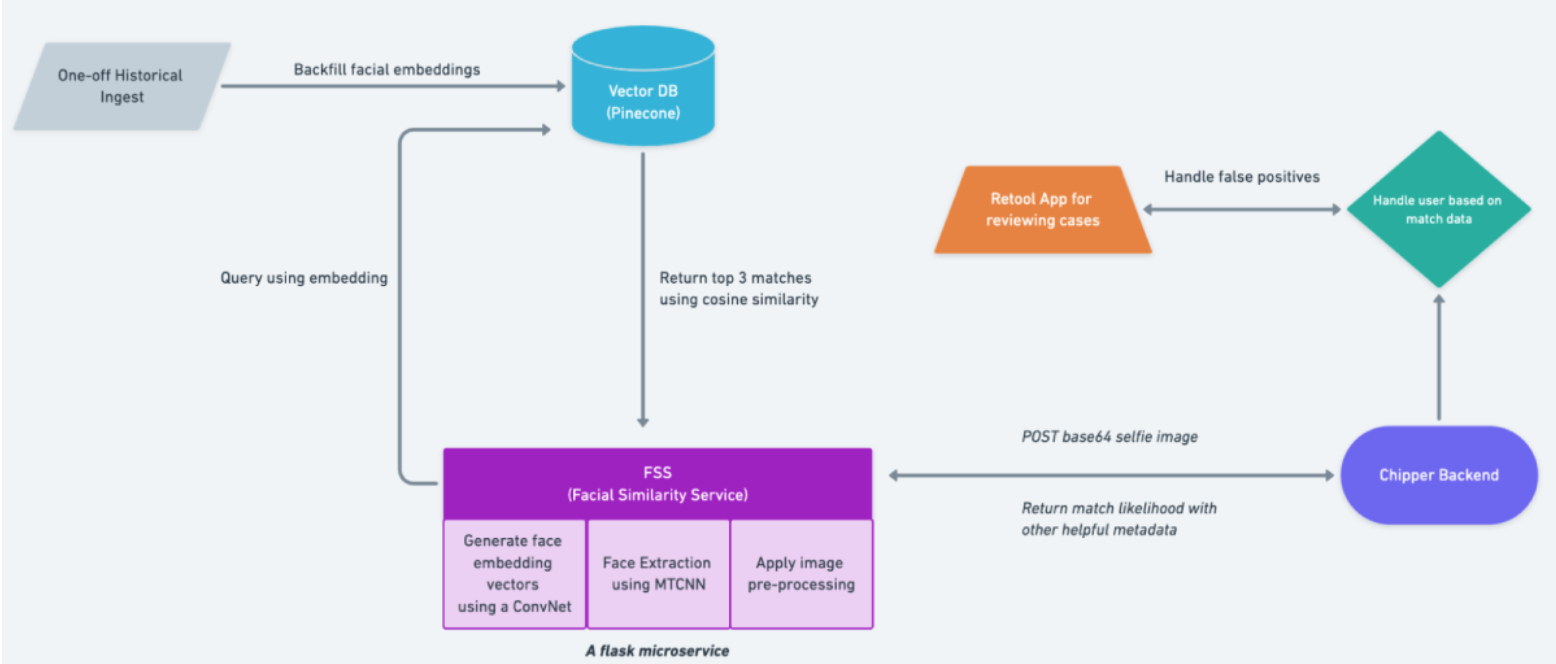
*来源:Chipper Cash*
● Facebook 一直在内部的许多产品中使用其名为FAISS(博客)的矢量搜索库,包括Instagram Reels和 Facebook Stories,以快速查找任何多媒体并找到类似的候选者,以便向用户显示更好的建议。
# **结论**
矢量数据库对于构建各种 LLMs 应用程序非常有用,例如图像生成,电影或产品推荐以及聊天机器人。他们为 LLMs 提供 LLMs 尚未接受过培训的附加或类似信息。他们将向量嵌入有效地存储在高维空间中,并使用最近邻搜索以高精度查找相似的嵌入。
**关键要点**
本文的主要要点是矢量数据库非常适合 LLMs 应用程序,并为用户提供以下重要功能以供集成:
● 性能:矢量数据库专门设计用于高效存储和检索矢量数据,这对于开发高性能 LLMs 应用程序非常重要。
● 精度:矢量数据库可以准确匹配相似的矢量,即使它们表现出轻微的变化。他们使用最近邻算法来计算类似的向量。
● 多模态:矢量数据库可以容纳各种多模态数据,包括文本、图像和声音。这种多功能性使它们成为需要处理各种数据类型的LLMs /生成式AI应用程序的理想选择。
● 对开发人员友好:矢量数据库相对用户友好,即使对于可能不具备广泛机器学习技术知识的开发人员也是如此。
此外,我想强调的是,许多现有的 SQL / NoSQL 解决方案已经添加了向量嵌入存储,索引和相似性搜索功能,例如 PostgreSQL 和 Redis。
原文地址:https://www.analyticsvidhya.com/blog/2023/10/how-to-build-llm-apps-using-vector-database/
***
非常感谢大家的阅读,小Mo在这里祝你在末来的 Python 学习职业生涯中一切顺利!
后续小Mo会不定期更新书籍、视频等学习资源,以上这些书籍资料也可通过关注微信公众号免费获取哦!
欢迎关注我们的微信公众号:MomodelAl
同时,欢迎使用「Mo A编程」微信小程序
以及登录官网,了解更多信息:Mo 人工智能教育实训平台
Mo,发现意外,创造可能
注:部分资源来源于互联网,若有侵权,请直接联系作者删除。











评论 (0)