

在深度学习的领域,循环神经网络(RNN)和 Transformer 模型各有千秋。近期研究发现,线性循环模型(如 Mamba)凭借其优越的序列处理能力,正在逐渐挑战 Transformer 的地位。尤其是在处理极长序列的任务上,循环模型展现出了巨大的潜力,远远超出传统 Transformer 模型的局限性。
Transformer 模型在处理长上下文时,往往受到固定上下文窗口的限制,计算复杂度也随着序列长度的增加而迅速上升,导致性能下降。而线性循环模型则能够更灵活地处理长序列,这是它们的一大优势。然而,以往循环模型在短序列上的表现往往不及 Transformer,导致其在实际应用中受到限制。
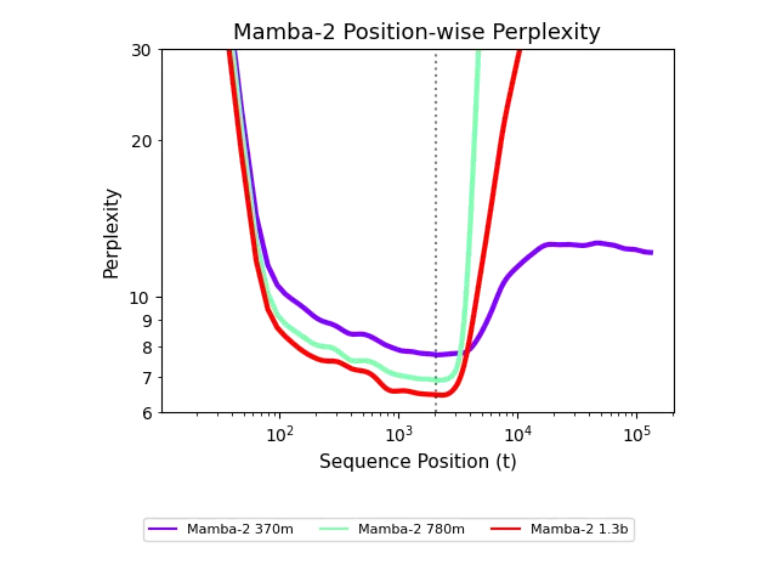
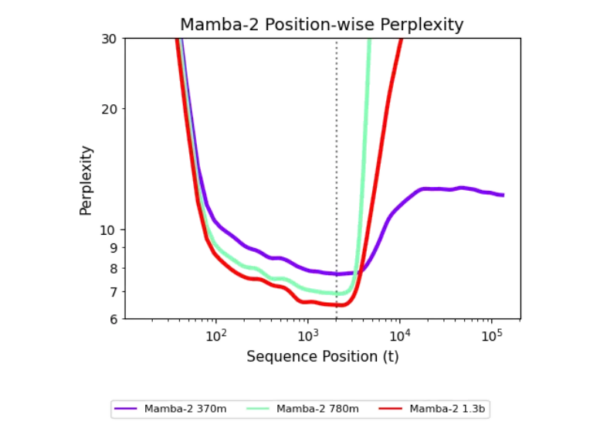
最近,来自卡内基梅隆大学和 Cartesia AI 的研究者们提出了一种创新的方法来提升循环模型在长序列上的泛化能力。他们发现,只需500步的简单训练干预,循环模型便能够处理长达256k 的序列,展现出惊人的泛化能力。这项研究表明,循环模型并非存在根本缺陷,而是其潜力尚未被充分挖掘。
研究团队提出了一个新的解释框架,称为 “未探索状态假说”。该假说指出,循环模型在训练过程中只接触到有限的状态分布,导致在面对更长序列时表现不佳。为了实现长度泛化,研究者们提出了一系列训练干预措施,包括使用随机噪声、拟合噪声和状态传递等方法。这些措施使得模型能够在长序列的训练中有效泛化,表现显著提升。
值得一提的是,这些干预方法不仅能提升模型的性能,还能保持状态的稳定性,使得循环模型在长上下文任务中表现出色。研究者们通过一系列实验,证明了这些方法在实际应用中的有效性,为循环模型的发展开辟了新的方向。












评论 (0)