

介绍
在快速发展的人工智能领域,围绕一个名为“现代人工智能扩散模型”的新概念引起了很多兴奋。这些模型就像人工智能的先驱,完成了曾经被认为非常困难的任务。在当今的人工智能环境中,扩散模型通过将随机噪声信号细化为复杂的高质量输出来产生数据的独特能力。与从简单分布中提取数据的传统生成模型不同,扩散模型遵循类似于扩散过程中信息的逐渐传播的迭代过程。

了解扩散模型
为了真正掌握扩散模型的力量和优雅,让我们深入研究它们的工作原理并探索一个实时示例。想象一下,你有一个随机的噪声信号,有点像旧电视屏幕上的静电。乍一看,这似乎毫无意义。但是,此噪声信号是您的画布,您希望将其转换为一幅美丽的画作,或者用 AI 术语来说,将其转换为与目标数据分布非常相似的图像。
扩散过程是你的艺术之旅。它首先采用这个嘈杂的画布,并将其与目标数据中的图像进行比较。现在,魔法在这里展开。通过一系列迭代步骤,噪声信号开始演变,几乎就像在暗室中显影的照片一样。在每一步中,噪声信号都更接近目标图像。这就像让艺术家微调每个像素,直到它们与真实图片相匹配。这种迭代改进是扩散模型的核心。
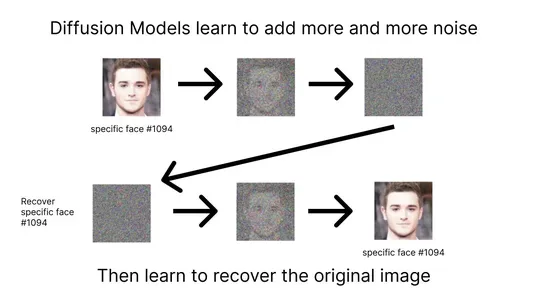
实时示例
让我们通过一个例子使这个概念更加具体。
想象一下,你有一个充满随机颜色的凌乱屏幕。看起来很混乱。这是你的起点。然后,您向模型展示一张华丽的日落图片,这就是您想要实现的目标。现在,模型开始调整凌乱屏幕上的像素颜色,使它们更像日落的温暖金色。它一直这样做,每走一步都越来越接近夕阳的颜色。这种情况一直持续到经过一系列尝试后,凌乱的像素变成了美丽的日落图像。
魔法背后的代码
现在,让我们看看幕后,看看一个简化的 Python 代码片段,它演示了这个扩散过程。
import numpy as np
def diffusion_model(noisy_canvas, target_image, num_iterations):
for i in range(num_iterations):
# Calculate the difference between noisy_canvas and target_image
difference = target_image - noisy_canvas
# Gradually update the noisy_canvas
noisy_canvas += difference / (num_iterations - i)
return noisy_canvas这个 Python 代码抓住了扩散模型的本质。它采用嘈杂的画布、目标图像和迭代次数作为输入。在每次迭代中,它计算画布和目标图像之间的差异,然后按此差异的一小部分更新画布。随着迭代的进行,画布变得更像目标图像。
扩散模型如何工作?
扩散模型通过将随机噪声信号迭代转换为与目标分布非常匹配的数据来运行。这个过程涉及几个步骤,每个步骤都细化噪声信号,以增加其与所需数据的相似性。这种迭代方法逐渐用结构化信息取代随机性,从而创建高质量的输出。

实现
import torch
import torch.nn as nn
import torch.optim as optim
# Define the diffusion model architecture
class DiffusionModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(DiffusionModel, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, output_dim)
def forward(self, noise_signal):
x = self.fc1(noise_signal)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x
# Initialize the diffusion model and optimizer
input_dim = 100 # Replace with your input dimension
hidden_dim = 128 # Replace with your desired hidden dimension
output_dim = 100 # Replace with your output dimension
model = DiffusionModel(input_dim, hidden_dim, output_dim)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Training loop
for epoch in range(num_epochs):
for batch_data in data_loader:
# Generate a random noise signal
noise_signal = torch.randn(batch_size, input_dim)
# Forward pass through the model
generated_data = model(noise_signal)
# Compute loss and backpropagate
loss = compute_loss(generated_data, target_data)
optimizer.zero_grad()
loss.backward()
optimizer.step()此代码定义了一个神经网络模型(扩散模型),其中包含用于处理数据的层。它初始化模型并设置用于训练的优化器。在训练期间,对于每批数据,它都会生成随机噪声,通过模型对其进行处理以创建输出,计算输出与我们想要的不同程度(损失),然后调整模型的参数以最小化这种差异(反向传播)。此过程重复多个时期,以提高模型在近似所需输出方面的性能。
扩散模型的应用
图像生成
扩散模型擅长生成高质量图像。它们已被用于创建令人惊叹的逼真艺术品,甚至从文本描述生成图像。
# Import the necessary libraries
import numpy as np
import torch
import torchvision.transforms as transforms
from PIL import Image
from torchvision.utils import save_image
# Load a pre-trained diffusion model
model = torch.load('pretrained_diffusion_model.pth')
model.eval()
# Generate an image from random noise
def generate_image():
z = torch.randn(1, 3, 256, 256) # Random noise as input
with torch.no_grad():
generated_image = model(z)
save_image(generated_image, 'generated_image.png')此代码使用预先训练的扩散模型生成图像。它从随机噪声开始,并将其转换为有意义的图像。生成的图像可以保存用于各种创意应用程序。
数据去噪
扩散模型可用于去噪图像和数据。它们可以有效地消除噪音,同时保留基本信息。
import numpy as np
import cv2
def denoise_diffusion(image):
grey_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
denoised_image = cv2.denoise_TVL1(grey_image, None, 30)
# Convert the denoised image back to color
denoised_image_color = cv2.cvtColor(denoised_image, cv2.COLOR_GRAY2BGR)
return denoised_image_color
# Load a noisy image
noisy_image = cv2.imread('noisy_image.jpg')
# Apply diffusion-based denoising
denoised_image = denoise_diffusion(noisy_image)
# Save the denoised image
cv2.imwrite('denoised_image.jpg', denoised_image)此代码清理嘈杂的图像,例如具有大量小点或颗粒感的照片。它将嘈杂的图像转换为黑白图像,然后使用特殊技术来消除噪声。最后,它将清理后的图像恢复为彩色并保存。这就像使用魔术滤镜来使您的照片看起来更好。
异常检测
使用扩散模型检测异常通常涉及比较模型重建输入数据的程度。异常通常是模型难以准确重建的数据点。
下面是一个简化的 Python 代码示例,使用扩散模型来识别数据集中的异常
import numpy as np
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
# Simulated dataset (replace this with your dataset)
data = np.random.normal(0, 1, (1000, 10)) # 1000 samples, 10 features
train_data, test_data = train_test_split(data, test_size=0.2, random_state=42)
# Build a diffusion model (replace with your specific model architecture)
input_shape = (10,) # Adjust this to match your data dimensionality
model = keras.Sequential([
keras.layers.Input(shape=input_shape),
# Add diffusion layers here
# Example: keras.layers.Dense(64, activation='relu'),
# keras.layers.Dense(10)
])
# Compile the model (customize the loss and optimizer as needed)
model.compile(optimizer='adam', loss='mean_squared_error')
# Train the diffusion model on the training data
model.fit(train_data, train_data, epochs=10, batch_size=32, validation_split=0.2)
reconstructed_data = model.predict(test_data)
# Calculate the reconstruction error for each data point
reconstruction_errors = np.mean(np.square(test_data - reconstructed_data), axis=1)
# Define a threshold for anomaly detection (you can adjust this)
threshold = 0.1
# Identify anomalies based on the reconstruction error
anomalies = np.where(reconstruction_errors > threshold)[0]
# Print the indices of anomalous data points
print("Anomalous data point indices:", anomalies)此 Python 代码使用扩散模型来查找数据中的异常。它从数据集开始,并将其拆分为训练集和测试集。然后,它构建一个模型来理解数据并对其进行训练。训练后,模型会尝试重新创建测试数据。它难以重新创建的任何数据都会根据所选阈值标记为异常。这有助于识别异常或意外的数据点。
图像到图像转换
从将白天场景更改为夜晚,再到将草图转换为逼真的图像,扩散模型在图像到图像转换任务中证明了它们的价值。
import torch
import torchvision.transforms as transforms
from PIL import Image
# Load a pre-trained diffusion model (this is a simplified example)
# You may need to download a pre-trained model or train your own.
diffusion_model = load_pretrained_diffusion_model()
input_img = 'inputimg.jpg'
input_img = Image.open(input_img)
# Preprocess the input image (resize, normalize, etc.)
transform = transforms.Compose([
transforms.Resize((256, 256)), # Resize to the model's input size
transforms.ToTensor(), # Convert to a tensor
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) # Normalize
])
input_image = transform(input_image).unsqueeze(0) # Add batch dimension
# Perform image-to-image translation using the diffusion model
with torch.no_grad():
translated_image = diffusion_model(input_image)
# Post-process the translated image if needed (e.g., denormalize)
translated_image = (translated_image + 1) / 2.0 # Denormalize to [0, 1]
# Save the translated image
translated_image_path = 'translated_image.jpg'
transforms.ToPILImage()(translated_image.squeeze(0)).save(translated_image_path)
print("Image translation complete. Translated image saved as:", translated_image_path)使用扩散模型的图像到图像转换是一项复杂的任务,涉及在特定数据集上为特定翻译任务训练扩散模型。上面的代码片段概述了使用扩散模型执行图像到图像转换的一般步骤。这是一个基本的简化示例。由于扩散模型的训练计算成本很高,因此在实际使用中通常首选预训练模型。
注意:“PIL”是 Pillow 库的模块。您可以使用“PIL 导入图像”导入它。“图像”是 Pillow 库提供的课程。
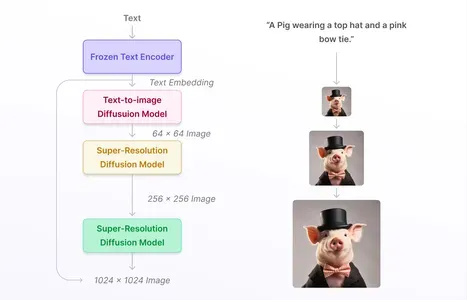
文本到图像扩散模型是扩散模型的专用变体,旨在从文本描述生成图像。这些模型将基于文本的信息的强大功能与扩散模型的生成功能相结合,以创建与提供的文本匹配的图像。
该过程通常涉及将文本描述编码为合适的格式,然后使用扩散模型将随机噪声信号迭代细化为与描述一致的图像。这项技术在各个领域都有应用,包括创意艺术品生成、产品设计,甚至是视障人士的辅助工具。它弥合了自然语言理解和图像生成之间的差距,使其成为现代人工智能应用中的宝贵工具。
注意:对文本进行编码(这将是涉及自然语言处理模型的更复杂的步骤)。
对人工智能进步的影响
扩散模型的出现为人工智能的未来开辟了令人兴奋的可能性:
● 增强创造力: 扩散模型可以提高人工智能的创造能力,使其能够生成无与伦比的艺术、音乐和内容。
● 强大的数据处理功能:这些模型可以更有效地处理嘈杂的数据,增强人工智能系统在现实世界中不完美条件下的性能。
● 科学发现: 在科学研究中,扩散模型可以帮助模拟复杂系统并生成数据,有助于假设测试和发现。
● 改进的自然语言处理: 扩散模型的迭代性质可以有利于语言理解,使它们成为NLP中潜在的游戏规则改变者。
挑战和未来方向
虽然扩散模型前景广阔,但它们也带来了挑战:
● 复杂性:训练和使用扩散模型可能是计算密集型和复杂的。
● 大规模部署:将扩散模型大规模集成到实际应用中需要进一步开发。
● 道德考虑: 与任何人工智能技术一样,必须解决有关数据使用和潜在偏见的伦理问题。
结论
扩散模型正在开创人工智能功能的新时代。他们独特的数据生成和转换方法为广泛的应用打开了大门,从艺术努力到科学突破。随着研究人员和工程师继续完善和利用扩散模型的力量,我们可以期待在不久的将来出现更多惊人的人工智能创新。人工智能的旅程注定是令人兴奋的,扩散模型处于这一非凡旅程的最前沿。

关键要点
● 扩散模型将随机噪声转换为类似于目标的复杂数据。
● 它们以迭代方式细化噪声以创建高质量的输出。
● 应用:图像生成、数据去噪、异常检测、图像到图像转换。
● 文本到图像扩散模型结合了文本和图像。
● 它们增强了创造力,更好地处理数据,帮助科学并改善了自然语言处理。
常见问题
Q1:是什么让扩散模型在人工智能中独一无二?
答:扩散模型在人工智能中很特殊,因为它们可以逐渐将随机性转化为有价值的数据。这种逐步转换功能使它们与众不同,并使它们可用于为图像生成和降噪等任务创建高质量输出。
Q2:扩散模型如何用于图像生成?
答:为了创建图像,扩散模型不断调整随机噪声,直到它看起来像我们想要的目标图像。他们通过逐渐调整噪声来做到这一点,使其越来越像所需的图像,从而生成逼真和高质量的图像。
Q3:扩散模型在数据去噪中扮演什么角色?
答:扩散模型就像数据清理器。它们可以从数据中删除不需要的噪音,同时保持重要信息完好无损。这使得它们对于清理嘈杂的图像或数据集非常有帮助。
Q4:为什么异常检测和扩散模型是互联的?
答:扩散模型非常擅长发现异常事物,因为它们了解正常数据的样子。这种连接对于识别各个领域(例如金融或网络安全)中的异常或奇怪的数据点非常方便,在这些领域中检测异常值至关重要。
原文地址:https://www.analyticsvidhya.com/blog/2023/09/unraveling-the-power-of-diffusion-models-in-modern-ai/
非常感谢大家的阅读,小Mo在这里祝你在末来的 Python 学习职业生涯中一切顺利!
后续小Mo会不定期更新书籍、视频等学习资源,以上这些书籍资料也可通过关注微信公众号免费获取哦!
欢迎关注我们的微信公众号:MomodelAl
同时,欢迎使用「Mo AI编程」微信小程序
以及登录官网,了解更多信息:Mo 人工智能教育实训平台
Mo,发现意外,创造可能
注:部分资源来源于互联网,若有侵权,请直接联系作者删除。












评论 (0)