

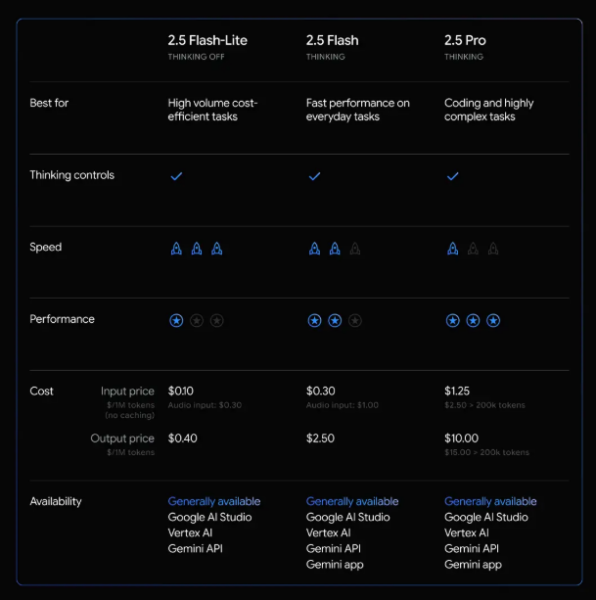
近日,谷歌正式宣布其最新的 Gemini2.5Flash-Lite 模型已进入稳定版本(GA)。这一版本被称为是速度最快、成本最低的模型,标志着谷歌在人工智能领域的又一重要进展。Gemini2.5Flash-Lite 在性能和成本之间取得了良好的平衡,能够原生支持高达100万 token 的上下文,带来了诸多高级功能。
Gemini2.5Flash-Lite 的定价策略也相当引人注目:每百万输入 token 的费用仅为0.10美元,而每百万输出 token 的费用为0.40美元,这与竞争对手 GPT-4.1Nano 的价格相当。此外,相较于早期的预览版,这一模型在音频输入方面的定价降低了40%,显示出其对用户需求的敏感度和对市场竞争的回应。
在各项基准测试中,Gemini2.5Flash-Lite 的表现超越了之前的2.0版本,涵盖了编码、数学、推理和多模态理解等多个领域。该模型支持100万 token 的上下文窗口,具备可控的思考预算(thinking budgets),并提供多种原生工具,如与 Google 搜索的结合、代码执行以及 URL 上下文的功能。
开发者们可以通过简单的代码指令使用 Gemini2.5Flash-Lite 模型,具体方式是指定模型为 gemini-2.5-flash-lite。需要注意的是,原有的预览版别名计划将于8月25日移除,开发者们应尽快适应新的版本。
此次 Gemini2.5Flash-Lite 的发布,标志着谷歌在人工智能技术方面不断创新和优化的决心,为开发者提供了更加高效且经济实惠的选择,未来无疑会在多种应用场景中发挥更大的作用。
划重点:
🌟 Gemini2.5Flash-Lite 是谷歌最新发布的速度最快、成本最低的 AI 模型,已进入稳定版本(GA)。
💰 该模型每百万输入 token 定价为0.10美元,每百万输出 token 定价为0.40美元,相比预览版音频输入价格降低了40%。
🔧 开发者可通过指定模型名 gemini-2.5-flash-lite 使用新版本,原有预览版别名将于8月25日移除。












评论 (0)