


近期,一款名为dots.ocr的多语言文档解析模型引发了AI领域的广泛关注。这款基于1.7B参数的轻量化视觉-语言模型,以其出色的性能和统一布局检测与OCR能力,成为文档处理领域的新星。
轻量高效:1.7B参数实现SOTA性能
dots.ocr基于仅1.7B参数的语言模型构建,相较于许多依赖更大模型的文档解析工具,其推理速度更快,处理单页PDF仅需数秒即可完成。尽管模型规模较小,dots.ocr在文本、表格和阅读顺序的解析上表现优异,达到了业界领先(SOTA)水平,其公式识别能力甚至可与Doubao-1.5和gemini2.5-pro等大型模型相媲美。这一高效性能使其成为开发者与企业的理想选择。

多语言支持:覆盖百种语言的强大能力
dots.ocr在多语言文档解析方面表现出色,尤其在低资源语言的处理上展现了显著优势。模型支持包括中文、英文在内的100种语言,能够准确识别多语言文档中的文本内容和布局元素。无论是处理多语言混合文档,还是应对复杂语言环境,dots.ocr都能提供稳定的解析效果,为全球化应用场景提供了强有力的支持。
精准布局检测:全面解析文档元素
在文档布局检测方面,dots.ocr展现了强大的能力。模型能够准确识别文档中的标题、段落、图片、表格等多种布局元素,并精确标注其位置和类别。得益于其统一的视觉-语言架构,dots.ocr避免了传统多模型流水线带来的复杂性,简化了处理流程,同时保持了良好的阅读顺序,确保解析结果符合文档的逻辑结构。
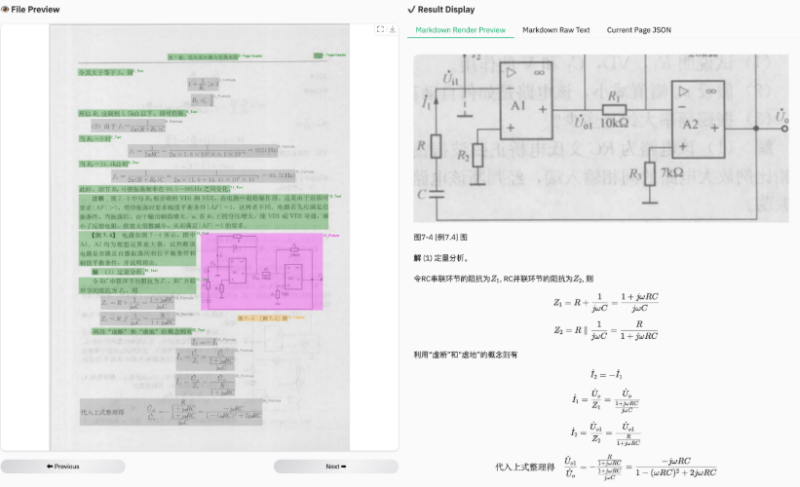
表格与公式解析:高精度与格式保留
dots.ocr在表格和公式解析上的表现尤为亮眼。模型能够精准检测表格的边界、单元格位置及内容,提取结果高度准确,适合处理结构化数据需求较高的场景。在公式识别方面,dots.ocr不仅能够处理复杂的数学公式,还能保留原始布局并输出为LaTeX格式,极大方便了学术研究和专业文档处理。尽管在特殊细节的处理上仍有优化空间,但其整体表现已足以媲美行业顶尖模型。
应用场景与局限性
dots.ocr的快速处理能力和多功能特性使其在多种场景中具备广泛应用潜力,例如文档数字化、学术研究、数据提取等。然而,当前模型在处理高复杂度的表格和公式时尚未完全完善,且对图片内容的解析暂不支持。此外,当文档字符像素比过高或包含连续特殊字符(如省略号或下划线)时,解析可能会出现问题,建议调整图像分辨率或使用特定提示词优化结果。开发团队表示,未来将进一步优化模型,增强表格、公式解析能力,并探索更通用的视觉-语言感知模型。
文档解析领域的创新标杆
我们认为dots.ocr的发布标志着文档解析技术迈向了新的高度。其轻量化设计、统一架构和多语言支持打破了传统OCR工具的局限,为开发者提供了更高效、灵活的解决方案。未来,随着模型在高吞吐量处理和复杂场景支持上的进一步优化,dots.ocr有望成为文档智能化的核心工具。结语dots.ocr以其1.7B参数的轻量架构、卓越的多语言解析能力和高效的处理速度,为文档处理领域注入了新的活力。从精准的布局检测到强大的表格与公式解析,这款模型正在重新定义AI驱动的文档解析体验。












评论 (0)