

在人工智能技术飞速发展的今天,中国科学院计算技术研究所自然语言处理团队推出了一款名为 Stream-Omni 的文本 - 视觉 - 语音多模态大模型。这一模型的核心亮点在于它能够同时支持多种模态的交互方式,为用户带来更加灵活和丰富的体验。
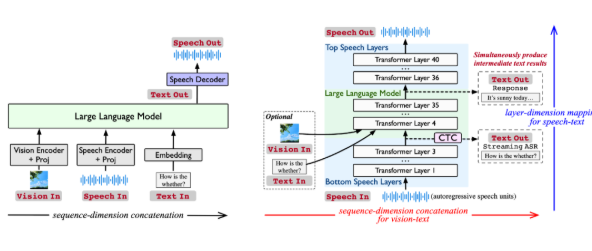
全面支持多模态交互
Stream-Omni 是一个基于 GPT-4o 架构的多模态大模型,展现了在文本、视觉和语音三种模态上的卓越能力。通过在线语音服务,用户不仅可以进行语音交互,还能在此过程中实时获取中间文本结果,使得交互体验更为自然,犹如 “边看边听”。
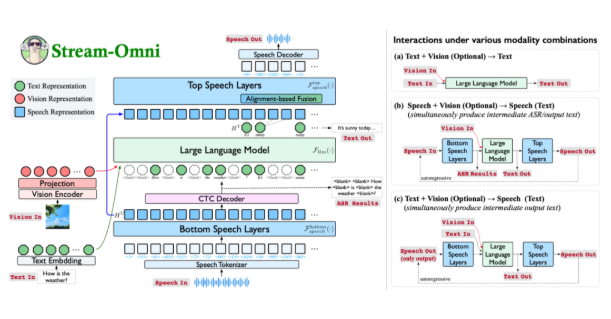
创新的模态对齐方式
现有多模态大模型通常通过将不同模态的表示拼接在一起,以输入到大语言模型中生成响应。然而,这种方法依赖于大量的数据,且缺乏灵活性。Stream-Omni 通过更有针对性的模态关系建模,减少了对大规模三模态数据的依赖。它强调语音与文本之间的语义一致性,并使视觉信息在语义上与文本互补,从而实现了更加高效的模态对齐。
强大的语音交互功能
Stream-Omni 独特的语音建模方式使其在语音交互过程中能够像 GPT-4o 一样,同时输出中间的文本转录结果。这一设计为用户提供了更全面的多模态交互体验,尤其在需要语音到文本实时转换的场景中,极大提升了效率和便利性。
实现任意模态组合的灵活交互
Stream-Omni 的设计允许通过灵活组合视觉编码器、语音层和大语言模型,支持多种模态组合的交互。这种灵活性使得用户能够在不同场景下自由选择输入方式,无论是文本、语音还是视觉,均可获得一致的响应。
在多项实验中,Stream-Omni 的视觉理解能力与同规模的视觉大模型相当,而其语音交互能力则显著优于现有技术。这种基于层级维度的语音 - 文本映射机制,确保了语音与文本之间的语义精确对齐,使得不同模态的响应更加一致。
Stream-Omni 不仅在多模态交互中提供了新思路,更以其灵活、高效的特性,推动了文本、视觉和语音技术的深度融合。尽管在拟人化表现和音色多样性上仍有待提升,但它无疑为未来的多模态智能交互奠定了坚实基础。
论文链接:https://arxiv.org/abs/2506.13642
开源代码:https://github.com/ictnlp/Stream-Omni
模型下载:https://huggingface.co/ICTNLP/stream-omni-8b
来源https://www.aibase.com/zh/












评论 (0)