

在回答这个问题之前,可以先简单地看一下这样一个视频,可以对GPU和CPU有大体上一个认识。[https://www.bilibili.com/video/BV1WW411u7qp](url)
你可能会感到疑惑为什么在视频中CPU效率比GPU低?
其实在早期的电脑并没有GPU,图像也是由CPU进行输出。随着计算机的发展,对实时图像和视频的需求大增,从而将图形模块从CPU中单独拎出变成了显卡。
**可以说CPU包揽了电脑中计算的所有部分,而GPU本是CPU中的一部分,特化了其图形计算部分。所以可以看到,CPU与GPU设计的方向本来就是不同的。**
CPU的设计目标:
- 非常强的通用性,以处理各种不同的数据类型
- 逻辑判断,从而引入大量分支跳转和中断
GPU的设计目标:
- 类型高度统一、相互无以来的大规模数据
- 不会中断的计算环境
所以也就导致
CPU:
- 核心数较少(通常几个到十几个),通用性较强
- 每个核都有足够大的缓存和足够多的数字和逻辑运算单元,并辅助有很多加速分支判断甚至更复杂的逻辑判断的硬件
GPU:
- 核心远超CPU(现在英伟达的高端卡卡通常有几千个了)
- 每个核拥有的缓存到校相对小,数字逻辑运算单元也较少
我们可以稍微深入的看一下这两个的构成: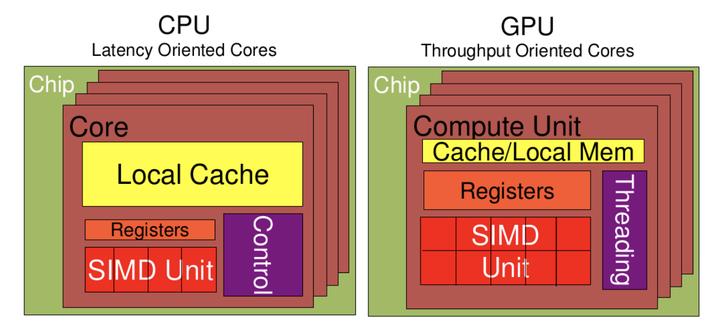
从上图可以看出:
Cache, local memory: CPU > GPU
Threads(线程数): GPU > CPU
Registers: GPU > CPU 多寄存器可以支持非常多的Thread,thread需要用到register,thread数目大,register也必须得跟着很大才行。
SIMD Unit(单指令多数据流,以同步方式,在同一时间内执行同一条指令): GPU > CPU。
以下两类程序适合在GPU上运行
- 计算密集型的程序。所谓计算密集型(Compute-intensive)的程序,就是其大部分运行时间花在了寄存器运算上,寄存器的速度和处理器的速度相当,从寄存器读写数据几乎没有延时。可以做一下对比,读内存的延迟大概是几百个时钟周期;读硬盘的速度就不说了,即便是SSD, 也实在是太慢了。
- 易于并行的程序。GPU其实是一种SIMD(Single Instruction Multiple Data)架构, 他有成百上千个核,每一个核在同一时间最好能做同样的事情。
回到神经网络中,现在的神经网络特别是是在深度学习中,数以千万计的参数,基本上都是计算密集重复型的任务。交给核心数众多的GPU最合适不过了。
当然现在也不是每台电脑都有GPU,现在部分电脑的CPU是集成了显卡的,这种显卡叫做核心显卡。它共用CPU的资源,使用内存作为显存。对于低负载的图形任务还是能胜任的,对于高负载的图形或者计算任务来说,它会和CPU的核心抢占资源,造成电脑的使用体验极差。它与专用GPU的性能差距极大。












评论 (0)