

介绍
生成式人工智能正在引领行业最新的技术浪潮。生成式 AI 应用程序,如图像生成、文本生成、摘要和问答机器人,仅举几例,正在蓬勃发展。由于 OpenAI 最近引领了大型语言模型浪潮,许多初创公司开发了工具和框架,允许开发人员使用这些 LLM 构建创新应用程序。其中一个工具是 LangChain,这是一个开发由 LLM 提供支持的应用程序的框架,具有可组合性和可靠性。LangChain 已成为全球 AI 开发人员构建生成 AI 应用程序的首选工具。LangChain 还允许连接外部数据源并与市场上可用的许多 LLM 集成。除此之外,LLM 驱动的应用程序需要一个矢量存储数据库来存储它们稍后将检索的数据。在这篇博客中,我们将通过使用 OpenAI API 和 ChromaDB 构建应用程序管道来了解 LangChain 及其功能。

语言链概述
LangChain 最近已成为大型语言模型应用程序的流行框架。LangChain 提供了一个复杂的框架来与 LLM,外部数据源,提示和用户界面进行交互。
LangChain 的价值主张
LangChain 的主要价值主张是:
● 组件: 这些是使用语言模型所需的抽象。组件是模块化的,易于用于许多 LLM 用例。
● 现成的链条:各种组件和模块的结构化组合,以完成特定任务,例如摘要,问答等。
项目详情
LangChain 是一个开源项目,自推出以来,该项目已经获得了超过 54K+ Github 的明星,这表明了该项目的受欢迎程度和可接受性。
项目自述文件以如下方式描述框架:
大型语言模型 (LLM) 正在成为一项变革性技术,使开发人员能够构建以前无法构建的应用程序。然而,单独使用这些 LLM 通常不足以创建一个真正强大的应用程序——当你将它们与其他计算或知识来源相结合时,真正的力量就会出现。
显然,它定义了框架的目的,旨在协助开发利用用户知识的应用程序。
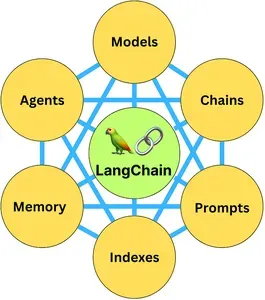
LangChain 有六个主要组件来构建 LLM 应用程序:模型 I/O、数据连接、链、内存、代理和回调。该框架还允许与许多工具集成以开发全栈应用程序,例如OpenAI,Huggingface Transformers 以及 Pinecone 和 chromadb 等 Vectors 商店。
组件的综合说明:
-
型号 I/O:与语言模型的接口。它由提示、模型和输出解析器组成
-
数据连接:使用数据转换器、文本拆分器、矢量存储和检索器与特定于应用程序的数据源进行交互
-
链:使用 AI 应用程序的其他组件构造一系列调用。链的一些示例是顺序链、摘要链和检索问答链。
-
代理:LangChain 提供了代理,允许应用程序根据用户输入利用对各种工具(包括LLM)的动态调用链。
-
记忆:在链运行之间保持应用程序状态
-
回调:记录和流式传输顺序链的步骤,以便有效地运行链并监控资源消耗
现在让我们看一下 LangChain 的一些用例。
-
针对特定文档的问答或聊天
-
聊天机器人
-
综述
-
代理
-
与 API 交互
这些是众多用例中的一小部分。我们将学习和开发一个语义搜索应用程序,用于使用 OpenAI API 和开源矢量数据库 ChromaDB 对特定文档进行问答。
环境设置和加载文档
现在,我们将使用 OpenAI 的 LLM API 为我们的语义搜索应用程序设置一个环境,以回答用户对一组文档的问题。我们在本文中使用示例文档,但您可以使用文档生成问答应用程序。首先,我们需要安装以下库:
安装项目依赖项
# install openai, langchain, sentense transfoers and other dependencies
!pip install openai langchain sentence_transformers -q
!pip install unstructured -q
# install the environment dependencies
!pip install pydantic==1.10.8
!pip install typing-inspect==0.8.0 typing_extensions==4.5.
!pip install chromadb==0.3.26LangChain 需要一些具有特定版本的环境依赖项,例如 pydantic、类型扩展和 ChromaDB。安装完成后,您可以在 colab 或任何其他笔记本环境中运行以下代码。
LangChain Document Loader
LangChain 提供文档加载器类,用于从用户输入或数据库加载文档。它支持各种文件格式,如 HTML,JSON,CSV 等。
# import langchain dir loader from document loaders
from langchain.document_loaders import DirectoryLoader
# directory path
directory = '/content/pets'
# function to load the text docs
def load_docs(directory):
loader = DirectoryLoader(directory)
documents = loader.load()
return documents
documents = load_docs(directory)
len(documents)
---------------------------[Output]----------------------------------------
[nltk_data] Downloading package punkt to /root/nltk_data...
[nltk_data] Unzipping tokenizers/punkt.zip.
[nltk_data] Downloading package averaged_perceptron_tagger to
[nltk_data] /root/nltk_data...
[nltk_data] Unzipping taggers/averaged_perceptron_tagger.zip.
5加载数据后,我们将使用文本拆分器将文本文档拆分为固定大小的块,以将它们存储在矢量数据库中。LangChain 提供多种文本拆分器,例如按字符拆分、按代码拆分等。
# use text splitter to split text in chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split the docs into chunks using recursive character splitter
def split_docs(documents,chunk_size=1000,chunk_overlap=20):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
docs = text_splitter.split_documents(documents)
return docs
# store the splitte documnets in docs variable
docs = split_docs(documents)将文档转换为块后,我们将在下一节中使用开源嵌入模型将它们嵌入到向量中。
使用 LangChain 和开源模型进行文本嵌入
嵌入文本是 LLM 应用程序开发管道中最重要的概念。所有文本文档都需要经过矢量化处理,然后才能用于语义搜索、摘要等任务。我们将使用开源句子转换器模型“all-MiniLM-L6-v2 ”进行文本嵌入。文档嵌入后,我们可以将它们存储在开源矢量数据库 ChromaDB 中以执行语义搜索。让我们看一下动手代码示例。
# embeddings using langchain
from langchain.embeddings import SentenceTransformerEmbeddings
embeddings = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
# using chromadb as a vector store and storing the docs in it
from langchain.vectorstores import Chroma
db = Chroma.from_documents(docs, embeddings)
# Doing similarity search using query
query = "What are the different kinds of pets people commonly own?"
matching_docs = db.similarity_search(query)
matching_docs[0]
--------------------------[output]----------------------------------------
Document(page_content='Pet animals come in all shapes and sizes,
each suited to different lifestyles and home environments.
Dogs and cats are the most common, known for their companionship
and unique personalities. Small mammals like hamsters, guinea pigs,
and rabbits are often chosen for their low maintenance needs.
Birds offer beauty and song, and reptiles like turtles and
lizards can make intriguing pets. Even fish, with their calming presence,
can be wonderful pets.',
metadata={'source': '/content/pets/Different Types of Pet Animals.txt'})在上面的代码中,我们使用嵌入来存储在 ChromaDB 中,它支持内存存储。因此,我们可以查询数据库以从文本文档中获取答案。我们询问了人们通常拥有的不同种类的宠物,并给出了正确的答案和答案的来源。
使用 OpenAI API、ChromaDB 和 LangChain 的生成式 AI 应用程序

使用 LangChain 和 OpenAI API 的语义搜索问答
此管道需要解释搜索词和文档的意图和上下文,以生成更精确的搜索结果。它可以通过理解用户意图、检查单词和概念之间的联系以及利用自然语言处理 (NLP) 中的注意力机制生成上下文感知搜索结果来提高搜索准确性。
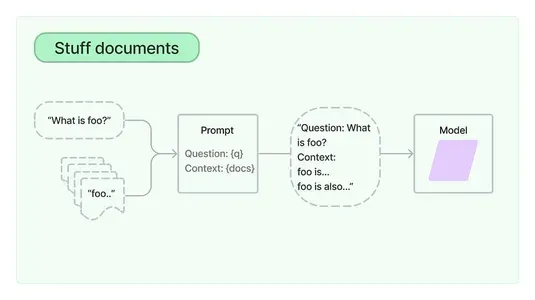
LangChain 提供了一个 OpenAI 聊天界面,用于将模型 API 调用到您的应用程序中,并创建一个问题/答案管道,根据给定的上下文或输入文档回答用户的查询。它基本上执行矢量化搜索以找到与问题最相似的答案。(请参阅下面的流程图)
# insert an openai key below parameter
import os
os.environ["OPENAI_API_KEY"] = "YOUR-OPENAI-KEY"
# load the LLM model
from langchain.chat_models import ChatOpenAI
model_name = "gpt-3.5-turbo"
llm = ChatOpenAI(model_name=model_name)
# Using q&a chain to get the answer for our query
from langchain.chains.question_answering import load_qa_chain
chain = load_qa_chain(llm, chain_type="stuff",verbose=True)
# write your query and perform similarity search to generate an answer
query = "What are the emotional benefits of owning a pet?"
matching_docs = db.similarity_search(query)
answer = chain.run(input_documents=matching_docs, question=query)
answer
-----------------------------------[Results]---------------------------------
'Owning a pet can provide numerous emotional benefits. Pets offer
companionship and can help reduce feelings of loneliness and isolation.
They provide unconditional love and support, which can boost mood and overall
well-being. Interacting with pets, such as petting or playing with them,
has been shown to decrease levels of stress hormones and increase the
release of oxytocin, a hormone associated with bonding and relaxation.
Pets also offer a sense of purpose and responsibility, as taking care of
them can give a sense of fulfillment and provide a distraction from daily
stressors. Additionally, the bond between pets and their owners can provide
a sense of stability and consistency during times of personal or societal
stress.'上面的代码使用 LangChain 的 ChatOpenAI() 函数调用“gpt-3.5-turbo”模型 API,并创建一个问答链来回答我们的查询。
使用法学硕士链生成公司名称
大型语言模型的另一个用例是使用 LLMChain、OpenAI LLM 和 LangChain 的 PromptTemplate 生成公司名称。您可以根据给定的描述作为提示生成公司或产品名称。请参考以下代码:
# import necessary components from langchain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# LLM by OpenAI
llm = OpenAI(temperature=0.9)
# Write a prompt using PromptTemplate
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)
# create chain using LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))
Output>>> Colorful Toes Co.**使用语言链的文本文档摘要
**链还允许开发文本摘要应用程序,这有助于法律行业汇总大量法律文件以加快司法程序。参考下面使用 LangChain 函数的示例代码:
# from langChain import load_suumarize_chain function and OpenAI llm
from langchain.llms import OpenAI
from langchain.chains.summarize import load_summarize_chain
# LLM by OpenAI
llm = OpenAI(temperature=0.9)
# create a chain instance with OpenAI LLM with map_reduce chain type
chain = load_summarize_chain(llm, chain_type="map_reduce")
chain.run(docs)LangChain 易于使用的界面解锁了许多不同的应用程序,并为最终用户解决了许多问题。如您所见,只需简单的几行代码,我们就可以利用 LLM 的强大功能来汇总来自 Web 上任何来源的任何数据。
结论
总之,这篇博客文章探讨了使用 LangChain 和 OpenAI API 构建生成式 AI 应用程序的令人兴奋的领域。我们看到了LangChain 的概述,它的各种组件以及 LLM 应用程序的用例。生成式 AI 彻底改变了各个领域,使我们能够生成逼真的文本、图像、视频等。语义搜索是一种用于使用 OpenAI LLM (如 GPT-3.5 和 GPT-4)构建问答应用程序的应用程序。让我们看看这个博客的关键要点:
-
我们了解了 LangChain 的简要概述 —— 一个用于构建 LLM 驱动的应用程序的开源框架。
-
我们学习了使用 LangChain 和 ChromaDB —— 一个矢量数据库来存储相似性搜索应用程序的嵌入。
-
最后,我们了解了 OpenAI LLM APIs,使用 LangChain 构建生成 AI 应用程序。
常见问题
问题 1.什么是生成式 AI?
答:生成式人工智能是一种机器学习技术,它从大量非结构化数据中学习,以生成新的文本、图像、音乐甚至视频。
问题 2.什么是语义搜索?
答:语义搜索应用程序需要解释搜索词和文档的意图和上下文,以在给定用户的特定查询时生成精确的搜索结果。
问题 3.什么是 LangChain,它的主要功能是什么?
答:LangChain 是大型语言模型应用程序开发中流行的框架。LangChain 提供了一个框架来与 LLM,外部数据源,提示和用户界面进行交互。
问题 4. LangChain 有什么好处?
答:LangChain 支持与各种外部数据源的连接。它还在各种用例中集成了 LLM,例如聊天机器人,摘要和代码生成。
问题 5. LangChain 支持哪些数据库?
答:LangChain 支持矢量数据库,如 ChromaDB 和 Pinecone,以及结构化数据库,如 MS SQL,MySQL,MariaDB,PostgreSQL,Oracle SQL 等。
非常感谢大家的阅读,小Mo在这里祝你在末来的 Python 学习职业生涯中一切顺利!
后续小Mo会不定期更新书籍、视频等学习资源,以上这些书籍资料也可通过关注微信公众号免费获取哦!
欢迎关注我们的微信公众号:MomodelAl
同时,欢迎使用「Mo AI编程」微信小程序
以及登录官网,了解更多信息:Mo 人工智能教育实训平台
Mo,发现意外,创造可能
注:部分资源来源于互联网,若有侵权,请直接联系作者删除。












评论 (0)