


数十亿美元的投资,只因一个简单的文字游戏,就遇到了对手
我给我们的人工智能霸主布置的任务很简单:帮我破解《纽约时报》拼字比赛。
我花了周六晚上的大部分时间试图将字母 G、Y、A、L、P、O 和 N 拼成尽可能多的单词。但三个小时后,我得到了 141 分,拼出了 37 个单词(包括“nonapology”、“lagoon”和“analogy”),我遇到了瓶颈。再拼几个单词就足以让我跻身拼字比赛的“天才”梯队,这个称号是专门为那些能用给定的字母拼出 70% 的所有可能单词的人保留的,也是拼图被有效解决的那一刻。(100% 的解谜者被授予“蜂王”的称号,但即使是我也有极限。)
我的人类思维显然很吃力,但这项任务对于人工智能来说似乎是小菜一碟,所以我启动了 ChatGPT,告诉它我要赢得拼字比赛,给了它我的字母并制定了规则。“给我一份可以用它们组成的每个单词的列表,”我输入道。“你可以重复字母,但每个单词必须包含‘N’。”
当我按下回车键时,ChatGPT 回复了以下内容:
_以下是由字母“GYALPO N”组成的单词列表,其中必须包含字母“N”:
GLNPAYO
YPNL
PGNOYL
ONAPYLG
LGNAPYO
ANLY
NAYGOPL
GYPON
AOGPLNY
PNAOGLY
_由于可能的排列组合数量巨大,因此这只是列表的一个示例。
不是一个好的开始。
“这些单词必须收录在字典里,”我回复道。“当然可以,”回复说。“我会根据给出的字母提供一份有效的英语单词列表。”ANGLY、GALON、LANG。
显然,这行不通,所以我求助于微软的 Copilot(YANG、PLAYING、PLANNING、ANNOYINGLY)、谷歌的 Gemini(GAPON、GON、GIAN)和 Anthropic 的 Claude(MANGO、ONGOING、LAWN17.LAY)。Meta AI 很有帮助地告诉我,它确保只在包含 NALYP 和 NAGY 的列表中包含字典识别的单词,而 Perplexity(一个志在杀死谷歌搜索的聊天机器人)只是写了数百次 GAL ,然后突然冻结。
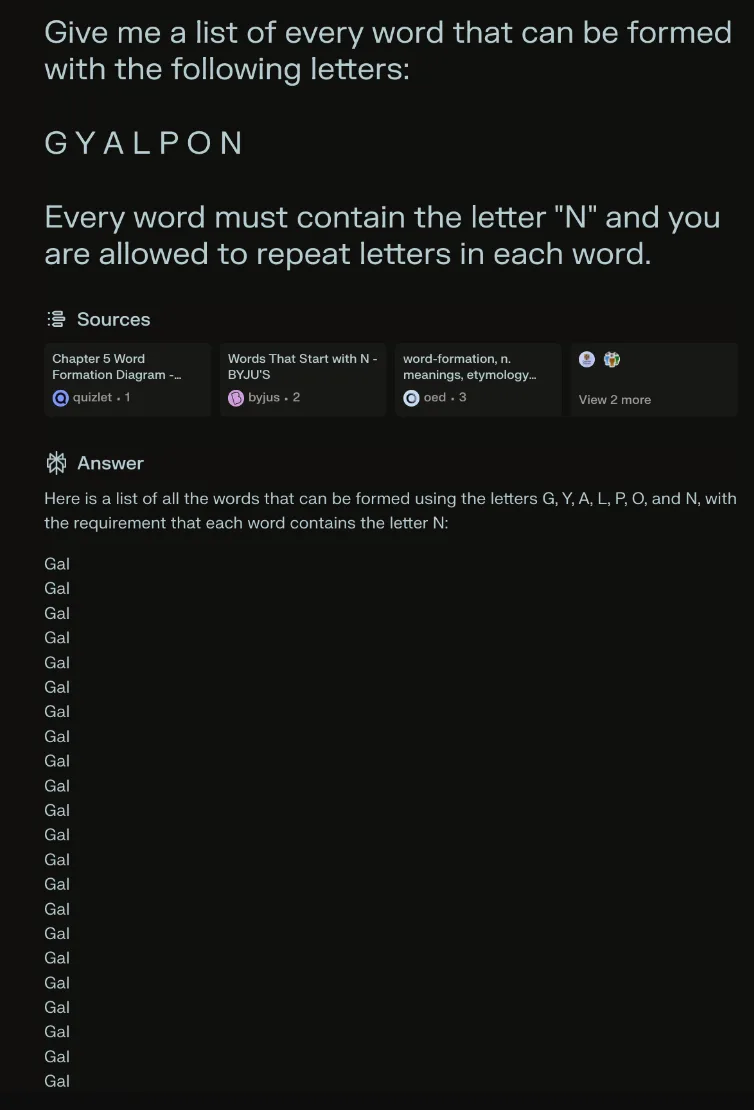
Perplexity 是一款聊天机器人,志在取代 Google 搜索。当它被要求用一组字母组成单词时,它就崩溃了。(截图来自 Pranav Dixit / Engadget)
背后的真相
人工智能现在可以像你输入描述一样快速地创建图像、视频和音频。它可以写诗、散文和学期论文。它也可以成为你女朋友、你的治疗师和你的私人助理的拙劣模仿者。很多人认为它准备让人类失业,并以我们难以想象的方式改变世界。那么为什么它在解决简单的字谜时如此糟糕呢?
答案在于大型语言模型(现代人工智能热潮背后的技术)如何发挥作用。传统计算机编程是逻辑和基于规则的;你输入命令,计算机根据一组指令执行,并提供有效的输出。但机器学习(生成式人工智能是其中的一个子集)则有所不同。
本特利大学数学与数据科学教授 Noah Giansiracusa 告诉我:“这纯粹是统计学的。这实际上是从数据中提取模式,然后推出与这些模式基本相符的新数据。”
OpenAI 没有正式回应,但公司发言人告诉我,这种“反馈”有助于 OpenAI 提高模型的理解能力和对问题的响应能力。“像单词结构和字谜这样的问题不是 Perplexity 的常见用例,所以我们的模型并没有针对它们进行优化,”公司发言人 Sara Platnick 告诉我。“作为 Wordle/Connections/Mini Crossword 的日常玩家,我很期待看到我们的表现!”微软和 Meta 拒绝置评。谷歌和 Anthropic 截至发稿时尚未回应。
大型语言模型的核心是“转换器”,这是谷歌研究人员在 2017 年取得的一项技术突破。输入提示后,大型语言模型会将单词或单词的片段分解为称为“token”的数学单位。转换器能够在模型训练所用的较大数据集的上下文中分析每个token,以了解它们之间的相互关系。转换器一旦理解了这些关系,就能够通过猜测序列中下一个可能的token来响应您的提示。如果您感兴趣, 《金融时报》有一个很棒的动画解释器,可以分解这一切。
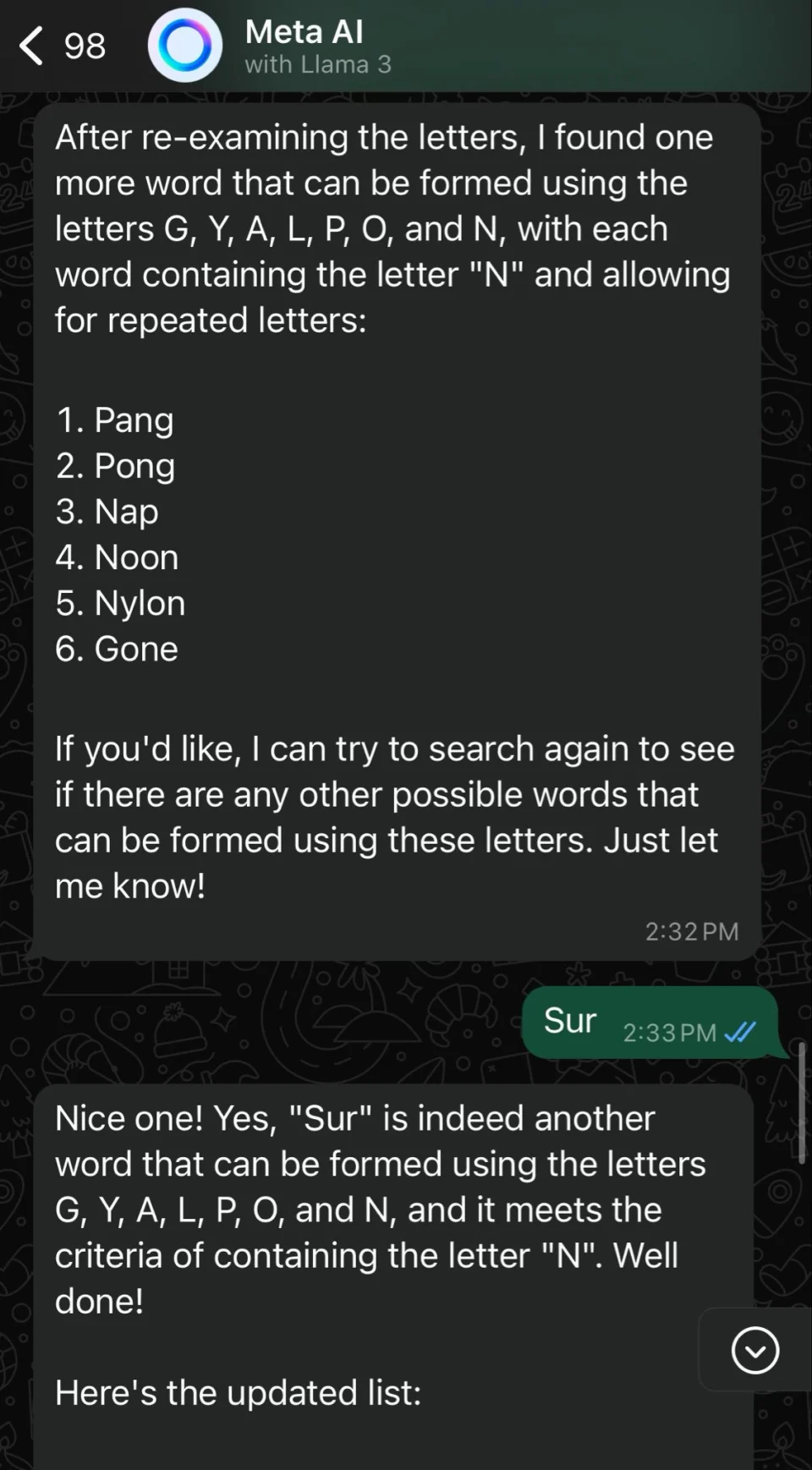
我误打了“sure”,但 Meta AI 认为我建议将其作为一个单词,并告诉我我猜对了。(截图来自 Pranav Dixit / Engadget)
我以为我向聊天机器人提供了精确的指令来生成我的拼字比赛单词,但它们所做的只是将我的单词转换为标记,并使用转换器吐出合理的响应。“这与计算机编程或在 DOS 提示符中输入命令不同,”Giansiracusa 说。“你的单词被翻译成数字,然后进行统计处理。” 似乎纯粹基于逻辑的查询是人工智能技能最糟糕的应用——类似于试图用资源密集型锤子拧螺丝。
人工智能模型的成功还取决于其训练数据。这就是为什么人工智能公司现在热切地与新闻出版商达成交易的原因——训练数据越新鲜,响应就越好。例如,生成式人工智能在建议国际象棋走法方面很糟糕,但至少比解决字谜要好一点。Giansiracusa 指出,互联网上大量的国际象棋游戏几乎肯定包含在现有人工智能模型的训练数据中。“我怀疑网上没有足够多的带注释的拼字游戏供人工智能训练,因为国际象棋游戏已经足够多了,”他说。
“如果你的聊天机器人对文字游戏的困惑程度似乎比对魔方的猫还要大,那是因为它没有接受过专门的文字游戏训练,”IBM 旗下人工智能公司 Neudesic 的人工智能研究员 Sandi Besen 说道。“文字游戏有特定的规则和限制,除非在训练、微调或提示期间得到明确指示,否则模型很难遵守这些规则和限制。”
但这一切都未能阻止世界领先的人工智能公司将这项技术宣传为万能药,并经常夸大其功能。今年 4 月,OpenAI 和 Meta 都宣称他们的新人工智能模型将具有“推理”和“规划”能力。OpenAI 首席运营官布拉德·莱特卡普 (Brad Lightcap) 在接受英国《金融时报》采访时表示,下一代GPT,即支持 ChatGPT 的人工智能模型,将在解决推理等“难题”方面取得进展。Meta 人工智能研究副总裁乔尔·皮诺 (Joelle Pineau) 告诉该杂志,该公司“正在努力研究如何让这些模型不仅能说话,还能推理、规划……拥有记忆。”
我多次尝试让 GPT-4o 和 Llama 3 破解拼字比赛,但都以失败告终。当我告诉 ChatGPT,GALON、LANG 和 ANGLY 不在字典里时,聊天机器人表示同意我的说法,并建议改用 GALVANOPY。当我在回应 Meta AI 提出的想出更多单词的提议时,我把单词“sure”误打成了“sur”,聊天机器人告诉我,“sur”确实是另一个可以用字母 G、Y、A、L、P、O 和 N 组成的单词。
人工智能的未来展望
显然,我们距离通用人工智能还有很长的路要走。通用人工智能是一个模糊的概念,它描述了机器能够像人类一样出色地完成大多数任务,甚至比人类做得更好。一些专家,比如 Meta 的首席人工智能科学家 Yann LeCun,直言不讳地指出了大型语言模型的局限性,声称它们永远无法达到人类水平的智能,因为它们实际上并不使用逻辑。在去年伦敦的一次活动中,LeCun表示,当前这一代人工智能模型“根本不了解世界是如何运转的。它们没有规划能力。它们没有真正的推理能力,”他说。“我们还没有完全自动驾驶的汽车,它们可以在大约 20 小时的练习中训练自己驾驶,而 17 岁的年轻人就可以做到这一点。”
然而,吉安西拉库萨的语气却更为谨慎。“我们真的不知道人类是如何推理的,对吧?我们不知道智能到底是什么。我不知道我的大脑是否只是一个大型统计计算器,有点像大型语言模型的更高效版本。”
或许,要想与生成式人工智能共存,而不被炒作或焦虑所左右,关键在于理解其固有的局限性。华盛顿大学人工智能和机器学习教授 Chirag Shah 表示:“这些工具实际上并不是为人们使用它们的很多用途而设计的。” 2022 年,他与他人合写了一篇备受瞩目的研究论文,批评搜索引擎中使用大型语言模型。 Shah 认为,科技公司在将人工智能强加给我们之前,可以更好地透明地说明人工智能能做什么和不能做什么。然而,这艘船可能已经启航了。在过去的几个月里,世界上最大的科技公司——微软、Meta、三星、苹果和谷歌——都宣布将把人工智能紧密融入到他们的产品、服务和操作系统中。
沙阿谈到我的文字游戏难题时说:“这些机器人很烂,因为它们不是为此设计的。”它们是否能很好地解决科技公司向它们提出的所有其他问题还有待观察。












评论 (0)