

欢迎来到【 AI 日报】栏目! 这里是你每天探索人工智能世界的指南,每天我们为你呈现 AI 领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新 AI 产品应用。
新鲜 AI 热点点击了解: https://momodel.cn/news
1、小米全量开源MiDashengLM-7B:音频理解性能刷新SOTA,推理速度暴增 20 倍
小米正式发布并全量开源了MiDashengLM-7B多模态大模型,该模型在音频理解领域实现了性能和效率的双重突破。其在 22 个公开评测集上取得最佳成绩,并且在推理效率方面表现出色,单样本首Token延迟仅为业界先进模型的四分之一,数据吞吐效率高出 20 倍以上。

【AiBase提要:】
🧠 双核心架构设计,融合专业音频处理与语言理解能力。
🎧 实现语音、环境声音和音乐的统一理解,提升跨域音频识别精度。
🚀 推理效率显著提升,支持终端离线部署,降低使用成本。
2、腾讯旗下AI工作台ima 推出全新功能,支持 AI 播客和文件夹导入等多项实用工具
腾讯旗下AI知识管理工具ima推出了多项新功能,包括AI播客生成、文件夹一键导入、Xmind脑图导入及知识库内容置顶,旨在提升用户的知识获取和管理体验。

【AiBase提要:】
🧠 支持AI播客生成,帮助用户更轻松地消化长篇文章或报告。
📁 提供一键导入文件夹功能,简化文档管理流程。
📌 可将重要文档置顶,提升信息检索效率。
3、阿里通义千问开源全新文生图模型Qwen-Image
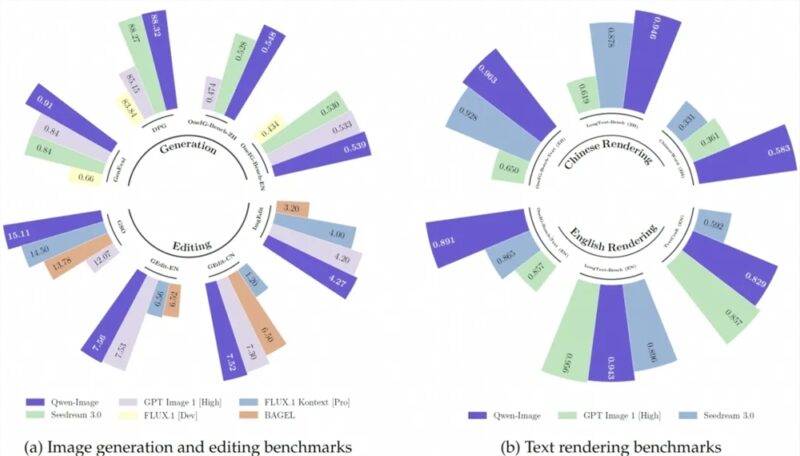
阿里通义千问开源了全新的文生图模型Qwen-Image,该模型在文本渲染和图像编辑方面表现出色,并在多个基准测试中取得领先性能,成为图像生成与编辑领域的重要突破。
【AiBase提要:】
🖼️ Qwen-Image支持多行布局、段落级文本生成及细粒度细节呈现,能精准渲染宫崎骏风格动漫场景和中文对联书法效果。
🎨 在图像编辑方面,Qwen-Image具备风格迁移、物体增减、细节增强等能力,使普通用户也能轻松实现专业级图像编辑。
📈 Qwen-Image在多个公开基准测试中表现卓越,尤其在中文文本渲染上大幅领先现有先进模型,展现了全面优势。
详情链接:https://modelscope.cn/models/Qwen/Qwen-Image
4、ChatGPT用户数暴涨至 7 亿创纪录新高,OpenAI年化收入飙升至 120 亿美元
文章详细介绍了ChatGPT的用户增长、商业化进展以及OpenAI的财务表现。同时提到GPT- 5 可能即将发布,以及与谷歌AI产品的竞争情况。此外,还强调了产品优化和对用户健康的关注。
【AiBase提要:】
🔥 ChatGPT周活跃用户达到 7 亿,同比增长超四倍。
💰 OpenAI年化收入达到 120 亿美元,远超预期。
💡 新增休息提醒功能,关注用户健康与体验提升。
5、Anthropic疑似开始内测Claude Opus 4.1:代号leopard暗示推理能力重大升级
文章指出,Anthropic正在对其下一代大语言模型Claude Opus 4. 1 进行内部测试,其内部代号为claude-leopard-v2-02-prod。新模型的宣传语强调了问题解决能力的显著提升,表明其在逻辑推理和复杂任务处理方面有重大突破。同时,该模型可能接近正式发布阶段,预计将在激烈的AI市场竞争中保持技术领先。
【AiBase提要:】
🧠 新模型Claude Opus 4. 1 主打问题解决能力,强化逻辑推理与复杂任务处理。
豹子命名暗示模型具备更快响应速度和精准分析能力,预示架构创新。
内测版本v2-02-prod表明模型已进入生产环境测试阶段,接近正式发布。
6、搭载 GLM-4.5!智谱推出 Zread.ai 开发效率工具,更快理解代码与生成文档
Zread.ai 是一款基于大语言模型的开发效率工具,旨在帮助开发者快速掌握项目结构、生成技术文档,并提升团队协作效率。其核心功能包括代码理解、知识生成和团队协作,利用 GLM-4.5 模型实现高效的代码分析和文档生成。
【AiBase提要:】
💡 Zread.ai 提供一站式代码理解与文档生成服务,帮助开发者快速掌握项目结构。
📚 自动生成项目导读,涵盖架构解析、模块说明等内容,提升文档撰写效率。
🔍 背后采用 GLM-4.5 模型,具有出色的代码理解能力和低误判率,支持深入技术问答。
7、xAI 发布 Grok Imagine4:支持文生图与视频生成,开放 NSFW 内容创作
xAI推出的Grok Imagine4 在文生图和图生视频方面表现出色,尤其以快速的生成速度和原生支持NSFW内容为亮点,但视频效果仍有提升空间。
【AiBase提要:】
🎨 文生图功能生成速度快,接近实时浏览体验。
🎬 图生视频效率高,但画面细节和流畅性有待优化。
🌶️ 原生支持NSFW内容生成,引发伦理讨论。
8、阿里巴巴与南开大学携手推出视频大模型新型压缩技术LLaVA-Scissor
LLaVA-Scissor 是一种创新的视频大模型压缩方法,由阿里巴巴通义实验室与南开大学计算机科学学院联合开发。该技术通过基于图论的SCC算法有效减少token数量,同时保留关键语义信息,显著提升了视频处理效率,并在多个视频理解基准测试中表现出色。
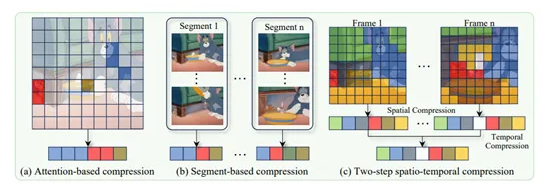
【AiBase提要:】
🌟 LLaVA-Scissor 是一种新型视频大模型压缩技术,旨在解决传统方法中token数量激增的问题。
🔍 SCC 方法通过计算token相似性,构建图并识别连通分量,从而减少token数量并保留关键语义信息。
🏆 LLaVA-Scissor 在低token保留率下展现出显著性能优势,尤其在视频问答和长视频理解任务中表现优异。
9、北京团队突破!全球首个人形机器人3D视觉系统诞生,多传感器融合技术领跑世界
文章介绍了北京人形机器人创新中心推出的Humanoid Occupancy视觉感知系统,该系统通过语义占用表征技术实现了对三维空间的精准建模和多传感器数据的高效融合,解决了人形机器人在复杂环境中的感知难题。

【AiBase提要:】
🌍 引入语义占用表征技术,实现对三维空间的精细化建模。
🔄 支持多模态传感器协同工作,提升环境信息整合能力。
📊 构建大规模数据集,为研究提供宝贵资源支持。
详情链接:https://arxiv.org/pdf/2507.20217
10、OpenMind推出机器人操作系统OM1:打造机器人领域的安卓,FABRIC协议实现机器人互联互通
OpenMind通过开发名为OM1 的机器人操作系统,致力于成为机器人领域的Android。其创新的FABRIC协议使机器人能够验证身份并共享信息,推动机器人间的协作与学习。
【AiBase提要:】
🤖 OpenMind专注于机器人软件生态,开发了OM1 操作系统,旨在成为机器人领域的Android。
🔗 FABRIC协议为机器人构建了一个信任和协作网络,提升群体智能的进化速度。
🏠 OpenMind选择家庭场景作为切入点,以满足对人性化交互的需求。












评论 (0)